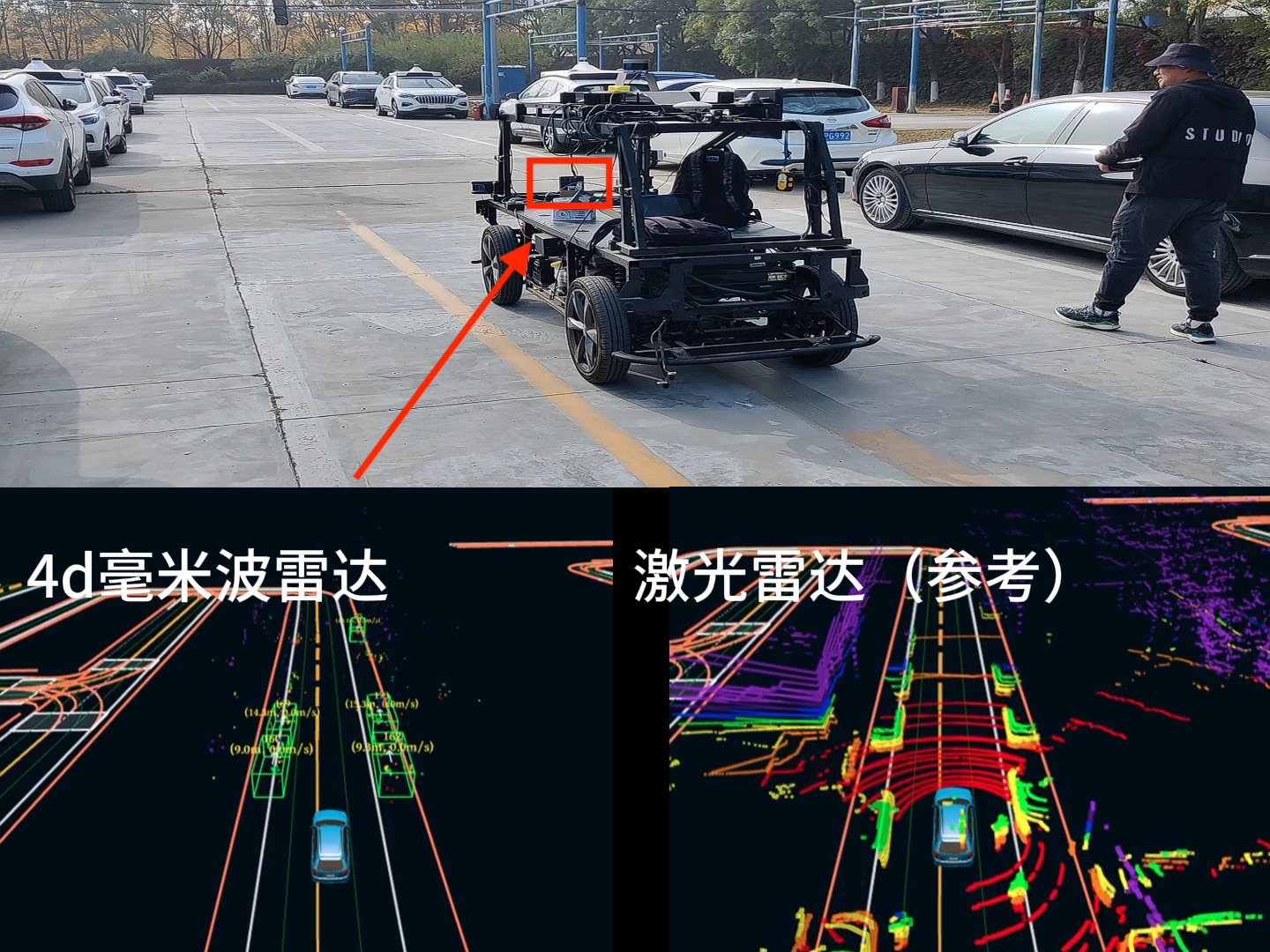
Beta 解读|【算法方向】支持4D毫米波,引入新模型提供增量训练
Apollo 新版本Beta已于11月6日正式开启公测。
Beta在Apollo 8.0的基础上对感知算法进行了升级优化,Lidar检测采用了比较新的CenterPoint模型并使用百度百万级数据进行训练,视觉上采用了Yolo X、Yolo 3D模型,检测效果和泛化性都得到了巨大提升,而且还提供了增量训练,支持独立自主进行模型训练。
另外,Beta感知增加了对4D毫米波的支持,障碍物检测和天气适应性都得到了极大增强,以下是此次算法升级的具体解读。
一、引入全新模型,算法检测效果显著提升
在Apollo 8.0时,我们联合Paddle 3D提供了端到端的自动驾驶模型开发解决方案,覆盖了从自动驾驶数据集到模型训练、模型评估和模型导出的算法开发全流程。
Beta在8.0版本基础上,对算法模型进行了更新升级,同时还在其他方面做了优化,模型泛化性和效果都得到了显著的提升。
1、更强大易用的激光雷达检测模型CenterPoint
在激光雷达检测方向,我们采用了新的CenterPoint模型替代了原来的CNNSeg模型,并依托于百度百万级的自动驾驶数据对模型进行了针对性优化,检测精度和召回率远超原CNNSeg模型,可以提供复杂城市道路场景下实时、准确、稳定的3D目标检测效果。
|检测效果示意

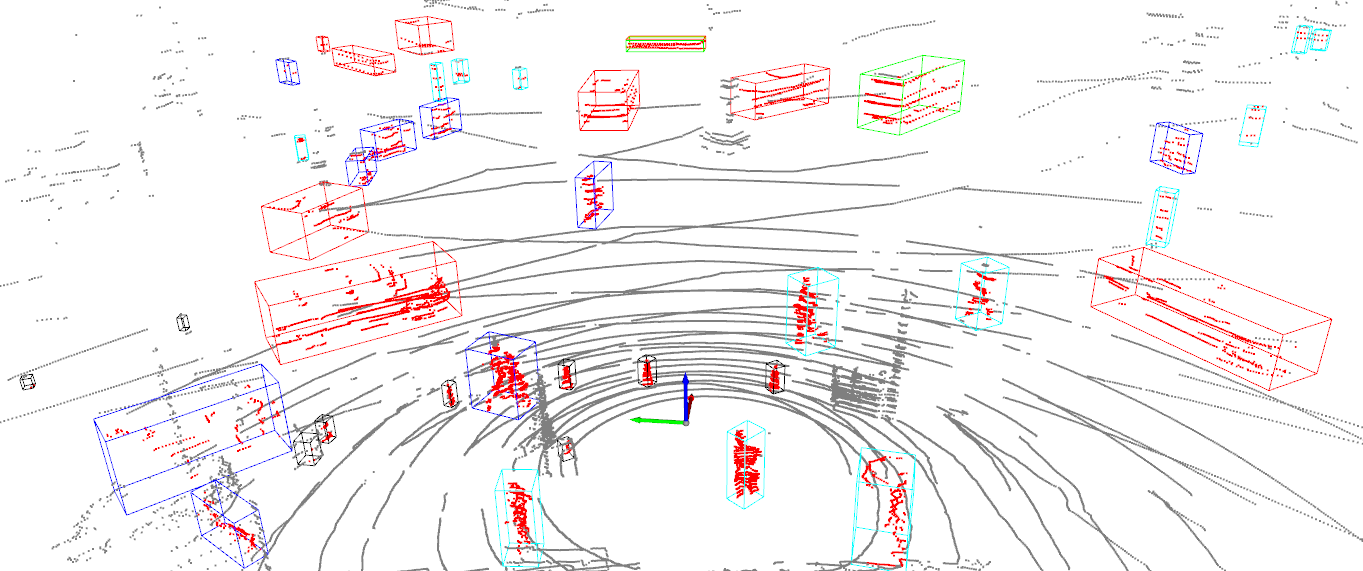
升级优化后,Beta激光雷达检测具备以下优势:
- 更好的检测效果,更强的泛化能力。Beta使用百万真实路测数据对CenterPoint进行训练和优化,精度和召回率相较于应用最多的CNNSeg模型提升了20%+,检测能力和泛化能力显著提升。
- 提供了常见城市道路标识的检测能力。Beta包括了锥桶、水马、防撞桶、指示牌等目标的检测能力,极大地保障了自动驾驶的安全性。
- 显著提升了近处行人目标和小目标的召回率。Beta对前后处理、配置、模型推理进行了针对性调优和处理,修复了推理端结果不一致问题,行人和小目标召回率提升。
- 增强了跟踪的稳定性。Beta优化了障碍物点云的获取逻辑,使CenterPoint可输出准确Polygon信息,进一步增强了跟踪的稳定性。
- 大幅降低模型推理耗时和GPU占用。Beta提供了Tensorrt + fp16推理 & Int8推理的功能和教程,在保持模型检测效果前提下,大幅降低了模型的推理耗时和GPU占用,在低算力平台运行可满足实时性要求。
- 降低训练开发成本,提升易用性。Beta开源了CenterPoint的训练代码,新增了以下功能:冻结网络层训练、fp16训练、适配自定义数据集等。开发者可以根据教程,使用公开/自定义数据集快速展开训练,大大降低了用户的训练开发成本,开发者可快速方便地开展模型训练部署、增量训练、Apollo感知赛事等任务。
|检测效果示意



2.相机检测,Yolo X+Yolo 3D更快更好用
在相机检测方向,视觉感知上我们使用了Yolo X+Yolo 3D两阶段模型替换了原来的Yolo单阶段模型,使得Beta的相机检测更易用、更好用,同时速度更快、效果更好。
具体来说,更换模型后Beta在相机检测方面进行了以下优化升级:
- 更易用。将单目3D目标检测任务完全解耦为2D框检测与3D姿态回归两个任务,能够满足开发者以插件的方式快速替换任意2D、3D模型的需求;(*Yolo系列模型部署时只需要简单适配前后处理即可实现模型的快速替换)
- 更好用。开源了Yolo X及Yolo 3D适配Apollo后的训练代码,并提供给开发者在开源数据及内部数据上的预训练模型,开发者可根据需求具体场景需求对模型进行Finetune;
- 更快速。新推出的Onnx推理框架提供了TensorRT的C++接口来完成模型部署,单阶段模型推理时间可降至1ms,大幅度提升了模型推理速度,助力开发者将自己的模型部署上车;
- 更强大。2D、3D模型均使用百万量级真实路测数据训练,在有效提升城市域全场景下目标的检测能力的同时二阶段预测出的目标朝向更加稳定、尺寸更加准确,相较于之前的Yolo模型在3D评测集上精度和召回率均提升了17%+。
|检测效果示意



二、提供增量训练,适应多种场景
针对开发者在自己场景中使用感知功能时可能会遇到,模型没有涉及过的特殊目标和特殊场景,出现模型目标检测效果不佳的情况。
为此Beta为开发者提供了全面详细的增量训练教程,开发者可使用少量自定义场景数据和Apollo预训练模型,在教程指导下进行增量训练,在维持模型原有检测能力的前提下,显著提升特殊目标和特殊场景的检测能力,从而达到用较低成本轻松提升定制场景的检测效果。
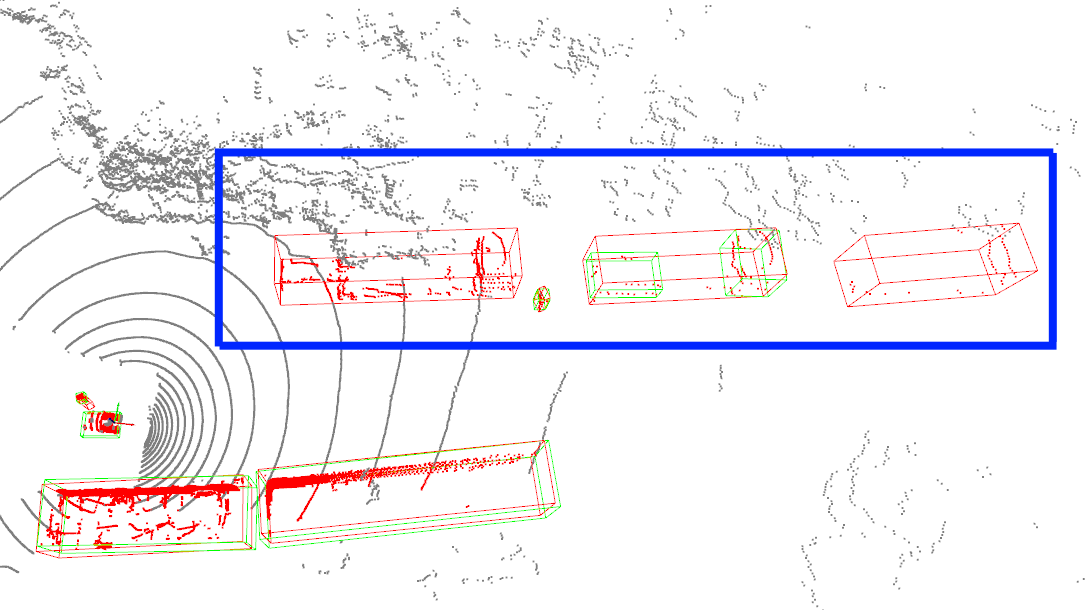
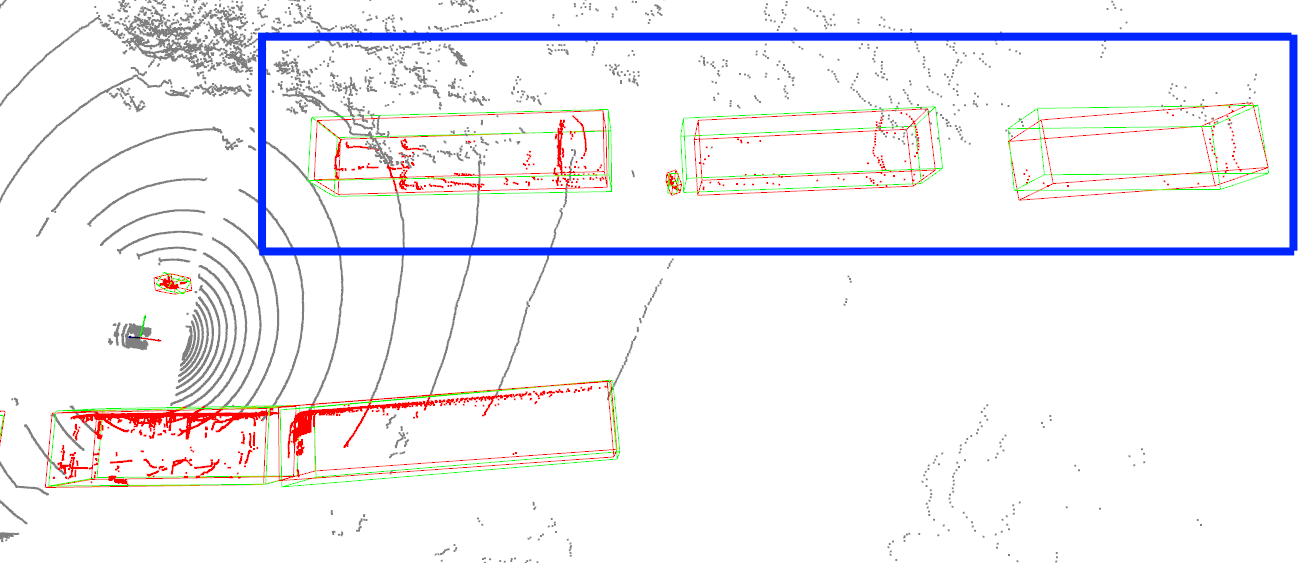
举例来说,我们采集了少量包含特殊挂车的自定义场景数据,使用增量训练方法解决特殊挂车检测效果差的问题。同时分别在百度城市道路数据和少量自定义场景数据中,评测模型原有的检测能力和新场景新目标的检测能力,最终给出指导性建议和意见:
- 冻结网络层。通过冻结特定网络层,对模型进行微调训练,缓解了灾难性遗忘问题(Catastrophic Forgetting),在保持模型原有检测能力的前提下,大幅提升了挂车的检测效果(自定义场景大车AP提升15%),有效解决了用户自动驾驶场景的痛点。
- 超参数调整。通过调整学习率、Epochs和Batch Size等超参数,可以进一步提升模型检测能力,同时更好地平衡在不同场景中的检测效果。
- 正则化。使用Object Smaple数据增强,正则化等技术,可有效避免在自定义数据集上的过拟合问题。
- 混合训练。同时将来会提供使用自定义数据集和百度数据集混合全量训练的功能,可在城市道路场景和自定义场景中同时获得最佳的检测效果(城市道路场景中mAP基本没有损失,自定义场景大车AP值提升25%)。
|效果展示

三、新增支持4D毫米波
Beta从硬件驱动到感知模型层,增加了对4D毫米波的支持。相比传统毫米波雷达,4D毫米波雷达新增俯仰角测量的能力,可以同时输出目标的水平角、俯仰角、距离、多普勒速度等信息,同时角分辨率可以提升至1度左右,输出类似于激光雷达的密集点云;通过基于深度学习模型的4D毫米波点云目标检测,提高自动驾驶车辆在雨雪雾等天气下的安全性。
Beta 4D毫米波具有以下亮点:
- 高精度。传统毫米波雷达只能返回二维平面的目标位置信息,对于天桥或减速带等目标,无法判断障碍物的高度信息,容易导致车辆急刹;而4D毫米波雷达可以返回点云的三维位置信息,对自动驾驶车辆周围环境进行更好的建模,更稳定地检测静态障碍物;
- 低误报。传统毫米波雷达只能返回稀疏的目标点云信息,无法分辨目标的几何特征,对于4D毫米波雷达输出的高密度点云,Apollo新增4D毫米波雷达目标检测模块,通过适配经典的点云目标检测模型PointPillars,利用毫米波点云特有的速度特征,通过多帧融合提升点云密度,对4D毫米波点云进行特征提取和目标检测,识别行人、车辆、非机动车等,避免了毫米波雷达噪点引起的误检,同时输出的障碍物的语义和Polygon等信息更有利于下游任务;
- 可迭代。开源了PointPillars适配Apollo后的训练代码,开发者可以迭代更适合毫米波雷达的深度目标检测网络,实现更高的毫米波雷达检测精度,充分释放毫米波雷达性能,实现更安全、成本更低的自动驾驶感知方案。
|检测效果示意