

apollo介绍之Cyber Scheduler调度(七)
Scheduler调度
所谓的调度,一定是系统资源和运行任务的矛盾,如果系统资源足够多,那么就不需要调度了,也没有调度的必要。调度的作用就是在资源有限的情况下,合理利用系统资源,使系统的效率最高。
Scheduler* Instance()
在""中实现了"Scheduler* Instance()"方法,该方法根据"conf"目录中的配置创建不同的调度策略。Cyber中有2种调度策略"SchedulerClassic"和"SchedulerChoreography"。要理解上述2种模型,可以参考go语言中的GPM模型。
- SchedulerClassic 采用了协程池的概念,协程没有绑定到具体的Processor,所有的协程放在全局的优先级队列中,每次从最高优先级的任务开始执行。
- SchedulerChoreography 采用了本地队列和全局队列相结合的方式,通过"ChoreographyContext"运行本地队列的线程,通过"ClassicContext"来运行全局队列。
基本概念
1.GPM模型
GPM模型是go语言中的概念,G代表协程,P代表执行器,M代表线程。P代表协程执行的环境,一个P绑定一个线程M,协程G根据不同的上下文环境在P中执行,上述的设计解耦了协程和线程,线程和协程都只知道P中,在go语言中还有一个调度器,把具体的协程分配到不同的P中,这样就可以在用户态实现协程的调度,同时执行多个任务。
在go语言早期,只有一个全局的协程队列,每个P都会从全局队列中取任务,然后执行。因为多个P都会去全局队列中取任务,因此会带来并发访问,需要在全局队列中加锁。全局队列调度模型如图。
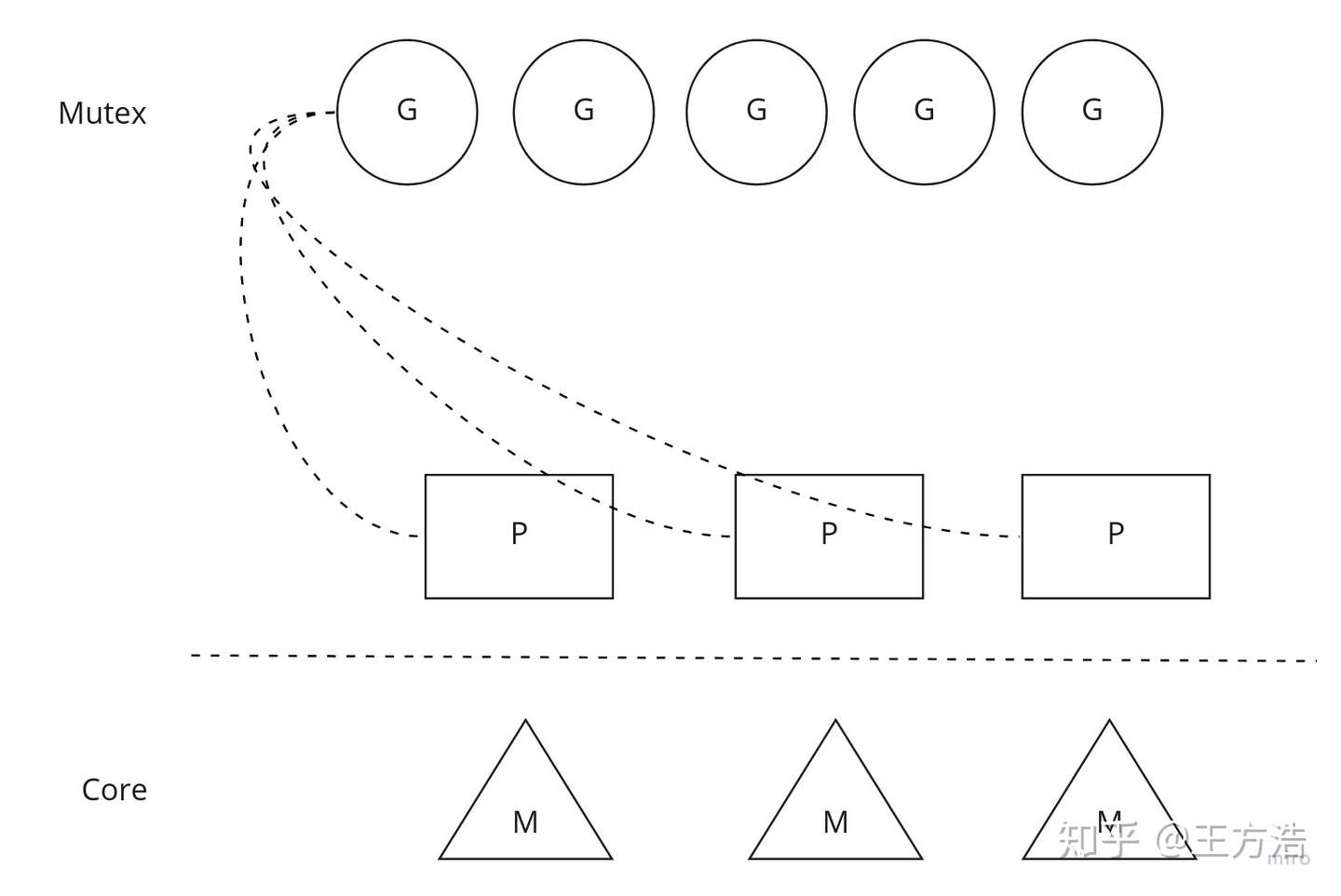
全局队列模型
上述方法虽然实现了多个任务的调度,但是带来的问题是多个P都会去竞争全局锁,导致效率低下,之后go语言对调度模型做了改善,改善之后每个P都会拥有一个本地队列,P优先从本地队列中取任务执行,如果P中没有任务了,那么P会从全局或者相邻的任务中偷取一半的任务执行,这样带来的好处是不需要全局锁了,每个P都优先执行本地队列。另外调度器还会监视P中的协程,如果协程过长时间阻塞,则会把协程移动到全局队列,以示惩罚。本地队列加全局队列如图。
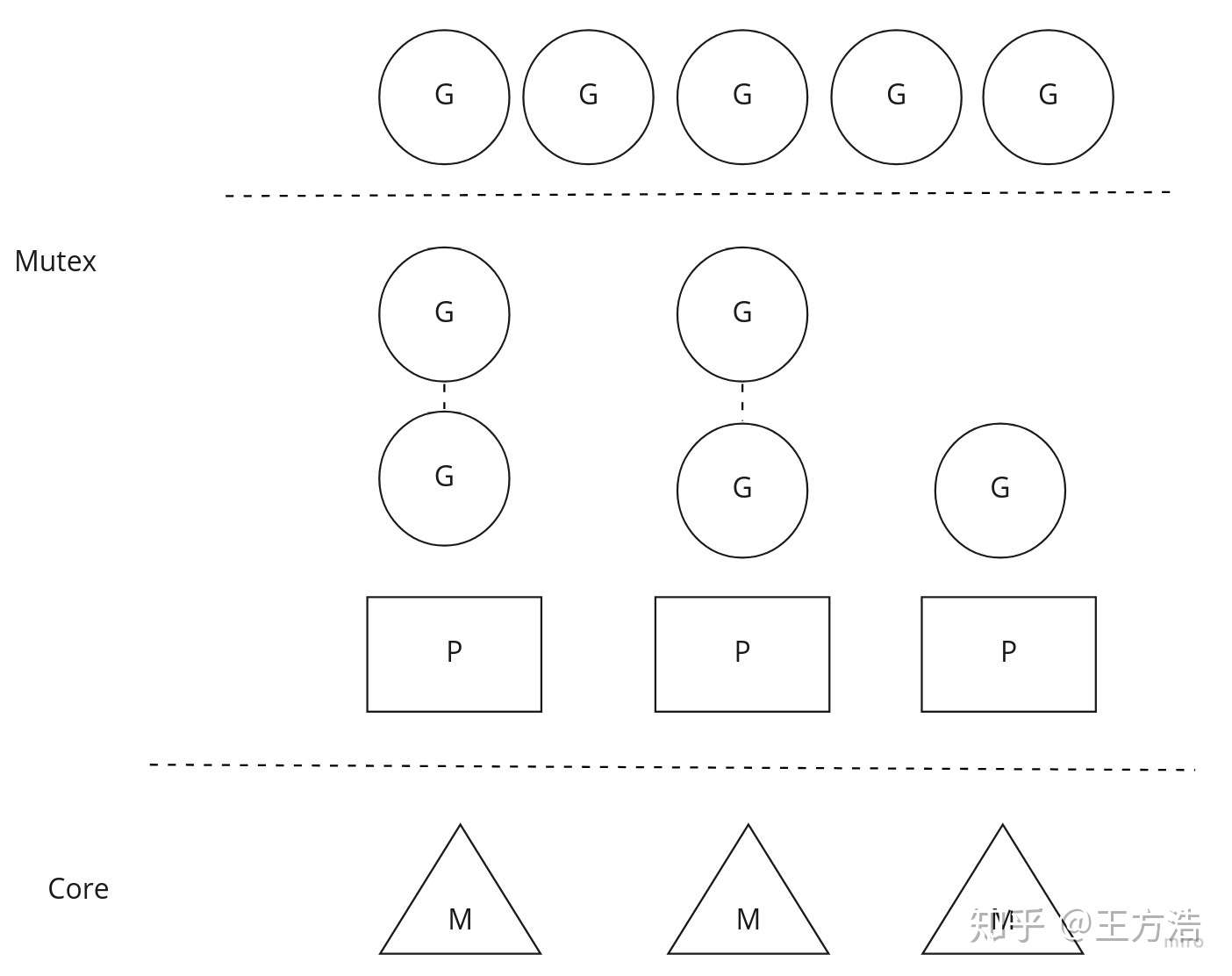
本地队列加全局队列模型
理解了GPM模型,下面我们接着看Cyber中的调度器,SchedulerClassic代表着全局队列模型,SchedulerChoreography则代表着本地队列加全局队列模型。SchedulerChoreography模型和go语言的模型稍微有点区别,全局队列和本地队列是隔离的,也就是说本地队列不会去全局队列中取任务。
2.Processor执行器
Processor执行器是协程的载体,对协程来说Processor就是逻辑的CPU。Processor中有协程执行的上下文信息,还有绑定的线程信息。先看下BindContext的实现。
voidProcessor::BindContext(conststd::shared_ptr<ProcessorContext>&context){// 1. 协程执行的上下文信息,会随着协程切换而切换
context_=context;// 2. 绑定Processor到具体的线程
std::call_once(thread_flag_,[this](){thread_=std::thread(&Processor::Run,this);});}
也就是说协程运行在Processor之上,切换协程的时候传入对应的上下文到Processor,然后Processor开始执行协程任务。下面看Processor是如何执行的。
voidProcessor::Run(){// 1. 获取线程的PID,系统内唯一
tid_.store(static_cast<int>(syscall(SYS_gettid)));snap_shot_->processor_id.store(tid_);while(cyber_likely(running_.load())){if(cyber_likely(context_!=nullptr)){// 2. 获取优先级最高并且准备就绪的协程
autocroutine=context_->NextRoutine();if(croutine){snap_shot_->execute_start_time.store(cyber::Time::Now().ToNanosecond());snap_shot_->routine_name=croutine->name();// 3. 执行协程任务,完成后释放协程
croutine->Resume();croutine->Release();}else{snap_shot_->execute_start_time.store(0);// 4. 如果协程组中没有空闲的协程,则等待
context_->Wait();}}else{// 5. 如果上下文为空,则线程阻塞10毫秒
std::unique_lock<std::mutex>lk(mtx_ctx_);cv_ctx_.wait_for(lk,std::chrono::milliseconds(10));}}}
疑问:
- 因为Processor每次都会从高优先级的队列开始取任务,假设Processor的数量不够,可能会出现低优先级的协程永远得不到调度的情况。
- 协程的调度没有抢占,也就是说一个协程在执行的过程中,除非主动让出,否则会一直占用Processor,如果Processor在执行低优先级的任务,来了一个高优先级的任务并不能抢占执行。调度器的抢占还是交给线程模型去实现了,cyber中通过调节cgroup来调节,保证优先级高的任务优先执行。
一共有2种ProcessorContext上下文"ClassicContext"和"ChoreographyContext"上下文,分别对应不同的调度策略。后面分析Scheduler对象的时候,我们会接着分析。
3.conf配置文件
Scheduler调度的配置文件在"conf"目录中,配置文件中可以设置线程线程的CPU亲和性以及调度测量,也可以设置cgroup,还可以设置协程的优先级。下面以"example_sched_classic.conf"文件来举例子。
scheduler_conf {// 1. 设置调度器策略policy: "classic"// 2. 设置cpu setprocess_level_cpuset: "0-7,16-23" # all threads in the process are on the cpuset// 3. 设置线程的cpuset,调度策略和优先级threads: [{name: "async_log"cpuset: "1"policy: "SCHED_OTHER" # policy: SCHED_OTHER,SCHED_RR,SCHED_FIFOprio: 0}, {name: "shm"cpuset: "2"policy: "SCHED_FIFO"prio: 10}]classic_conf {// 4. 设置分组,线程组的cpuset,cpu亲和性,调度测量和优先级。设置调度器创建"processor"对象的个数,以及协程的优先级。groups: [{name: "group1"processor_num: 16affinity: "range"cpuset: "0-7,16-23"processor_policy: "SCHED_OTHER" # policy: SCHED_OTHER,SCHED_RR,SCHED_FIFOprocessor_prio: 0tasks: [{name: "E"prio: 0}]},{name: "group2"processor_num: 16affinity: "1to1"cpuset: "8-15,24-31"processor_policy: "SCHED_OTHER"processor_prio: 0tasks: [{name: "A"prio: 0},{name: "B"prio: 1},{name: "C"prio: 2},{name: "D"prio: 3}]}]}}
下面我们开始看调度器,上述已经简单的介绍了2种调度器,SchedulerClassic是基于全局优先队列的调度器。
SchedulerClassic对象
我们知道协程实际上建立在线程之上,线程分时执行多个协程,看上去多个协程就是一起工作的。假如让你设计一个协程池,首先需要设置协程池中协程的个数,当协程超过协程池个数的时候需要把协程放入一个阻塞队列中,如果队列满了,还有协程到来,那么丢弃到来的协程,并且报错。(上述设计借鉴了线程池的思路)
1.创建Processor
调度器中首先会创建Processor,并且绑定到线程。调度器根据"conf"目录中的cgroup配置初始化线程,根据"processor_num"的个数创建多个Processor,并且绑定到线程。
voidSchedulerClassic::CreateProcessor(){// 读取调度配置文件,参照conf目录
for(auto&group:classic_conf_.groups()){// 1. 分组名称
auto&group_name=group.name();// 2. 分组执行器(线程)数量 等于协程池大小
autoproc_num=group.processor_num();if(task_pool_size_==0){task_pool_size_=proc_num;}// 3. 分组CPU亲和性
auto&affinity=group.affinity();// 4. 分组线程调度策略
auto&processor_policy=group.processor_policy();// 5. 分组优先级
autoprocessor_prio=group.processor_prio();// 7. 分组cpu set
std::vector<int>cpuset;ParseCpuset(group.cpuset(),&cpuset);for(uint32_ti=0;i<proc_num;i++){autoctx=std::make_shared<ClassicContext>(group_name);pctxs_.emplace_back(ctx);autoproc=std::make_shared<Processor>();// 8. 绑定上下文
proc->BindContext(ctx);// 9. 设置线程的cpuset和cpu亲和性
SetSchedAffinity(proc->Thread(),cpuset,affinity,i);// 10. 设置线程调度策略和优先级 (proc->Tid()为线程pid)
SetSchedPolicy(proc->Thread(),processor_policy,processor_prio,proc->Tid());processors_.emplace_back(proc);}}}
SchedulerClassic是Scheduler的子类,Scheduler中实现了"CreateTask"和"NotifyTask"接口,用于创建任务和唤醒任务。对用户来说只需要关心任务,Scheduler为我们屏蔽了Processor对象的操作。对应的子类中实现了"DispatchTask","RemoveTask"和"NotifyProcessor"的操作。
我们先看Scheduler如何创建任务。
boolScheduler::CreateTask(std::function<void()>&&func,conststd::string&name,std::shared_ptr<DataVisitorBase>visitor){autotask_id=GlobalData::RegisterTaskName(name);// 1. 创建协程,绑定func函数
autocr=std::make_shared<CRoutine>(func);cr->set_id(task_id);cr->set_name(name);AINFO<<"create croutine: "<<name;// 2. 分发任务
if(!DispatchTask(cr)){returnfalse;}// 3. 注册回调,visitor参数为可选的。
if(visitor!=nullptr){visitor->RegisterNotifyCallback([this,task_id](){if(cyber_unlikely(stop_.load())){return;}this->NotifyProcessor(task_id);});}returntrue;}
总结:
- 创建任务的时候只有对应数据访问的DataVisitorBase注册了回调,其它的任务要自己触发回调。
- DispatchTask中调用子类中的不同策略进行任务分发。
接着我们看SchedulerClassic的DispatchTask调度策略。
boolSchedulerClassic::DispatchTask(conststd::shared_ptr<CRoutine>&cr){// 1. 根据协程id,获取协程的锁
...// 2. 将协程放入协程map
{WriteLockGuard<AtomicRWLock>lk(id_cr_lock_);if(id_cr_.find(cr->id())!=id_cr_.end()){returnfalse;}id_cr_[cr->id()]=cr;}// 3. 设置协程的优先级和group
if(cr_confs_.find(cr->name())!=cr_confs_.end()){ClassicTasktask=cr_confs_[cr->name()];cr->set_priority(task.prio());cr->set_group_name(task.group_name());}else{// croutine that not exist in conf
cr->set_group_name(classic_conf_.groups(0).name());}// 4. 将协程放入对应的优先级队列
// Enqueue task.
{WriteLockGuard<AtomicRWLock>lk(ClassicContext::rq_locks_[cr->group_name()].at(cr->priority()));ClassicContext::cr_group_[cr->group_name()].at(cr->priority()).emplace_back(cr);}// 5. 唤醒协程组
ClassicContext::Notify(cr->group_name());returntrue;}
这里NotifyProcessor实际上就是唤醒对应Processor的上下文执行环境。
boolSchedulerClassic::NotifyProcessor(uint64_tcrid){if(cyber_unlikely(stop_)){returntrue;}{ReadLockGuard<AtomicRWLock>lk(id_cr_lock_);if(id_cr_.find(crid)!=id_cr_.end()){autocr=id_cr_[crid];if(cr->state()==RoutineState::DATA_WAIT||cr->state()==RoutineState::IO_WAIT){cr->SetUpdateFlag();}ClassicContext::Notify(cr->group_name());returntrue;}}returnfalse;}
疑问:
- 如果协程在等待IO,系统知道协程在等待io,但还是触发对应的协程组去工作。并没有让协程继续阻塞???
再看如何从"ClassicContext"获取Processor执行的协程。下图是全局协程队列的数据结构,为一个2级数组,第一级数组为优先级数组,第二级数组为一个队列。
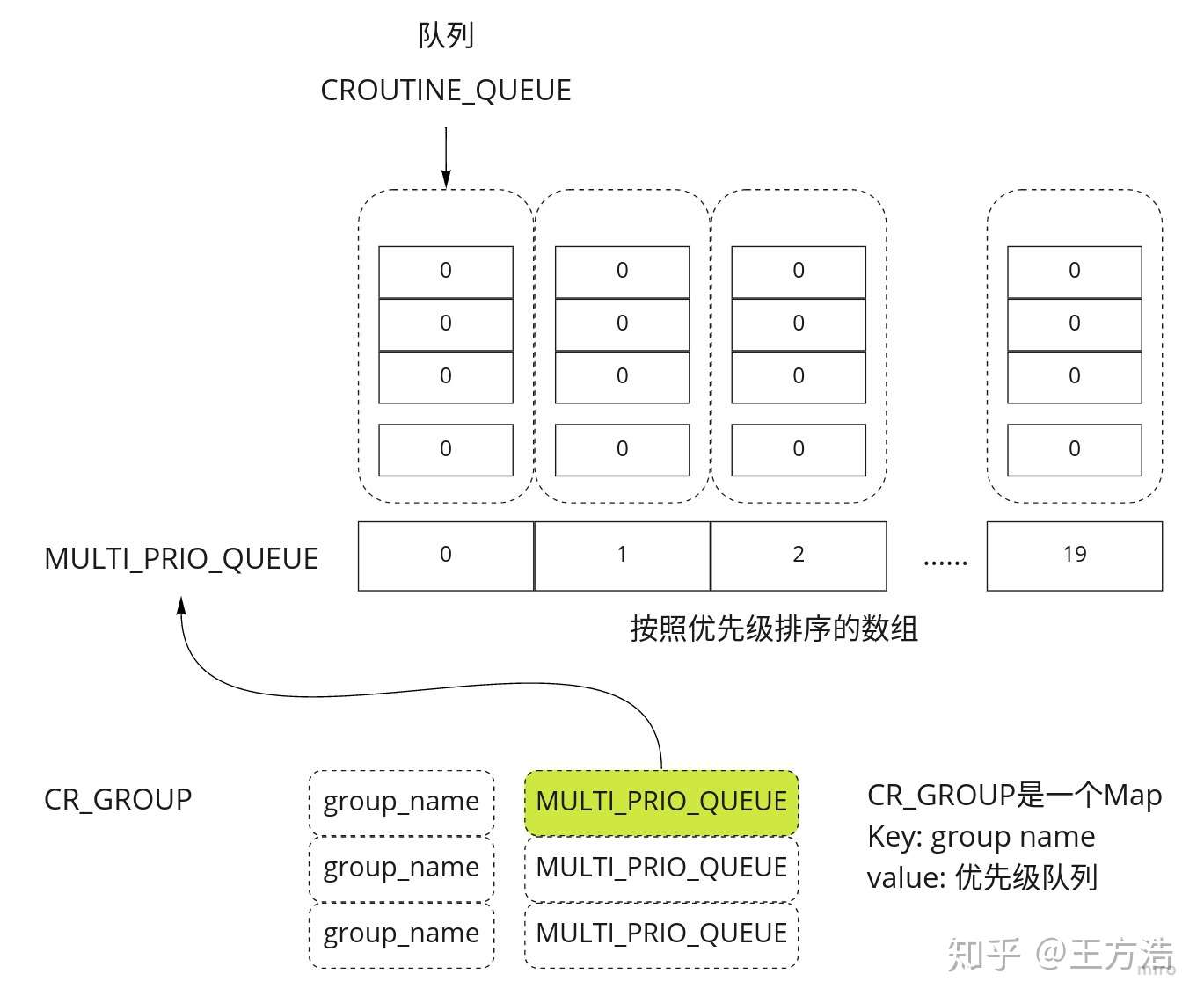
数据结构
std::shared_ptr<CRoutine>ClassicContext::NextRoutine(){if(cyber_unlikely(stop_.load())){returnnullptr;}// 1. 从优先级最高的队列开始遍历
for(inti=MAX_PRIO-1;i>=0;--i){// 2. 获取当前优先级队列的锁
ReadLockGuard<AtomicRWLock>lk(lq_->at(i));for(auto&cr:multi_pri_rq_->at(i)){if(!cr->Acquire()){continue;}// 3. 返回状态就绪的协程
if(cr->UpdateState()==RoutineState::READY){returncr;}cr->Release();}}returnnullptr;}
我们知道线程阻塞的条件有4种:
- 通过调用sleep(millseconds)使任务进入休眠状态
- 通过调用wait()使线程挂起
- 等待某个输入、输出流
- 等待锁
而Processor绑定的线程阻塞是通过上下文的等待实现的。在ClassicContext中等待条件(1s的超时时间),等待的时候设置notify_grp_减1。
voidClassicContext::Wait(){// 1. 获取锁
std::unique_lock<std::mutex>lk(mtx_wrapper_->Mutex());// 2. 等待条件大于0
cw_->Cv().wait_for(lk,std::chrono::milliseconds(1000),[&](){returnnotify_grp_[current_grp]>0;});// 3. 对应协程组的唤醒条件减1
if(notify_grp_[current_grp]>0){notify_grp_[current_grp]--;}}
Processor的唤醒也是通过上下文实现的。
voidClassicContext::Notify(conststd::string&group_name){// 1. 加锁
(&mtx_wq_[group_name])->Mutex().lock();// 2. 协程唤醒条件加1
notify_grp_[group_name]++;(&mtx_wq_[group_name])->Mutex().unlock();// 3. 唤醒线程
cv_wq_[group_name].Cv().notify_one();}
关于SchedulerClassic我们就先介绍到这里,下面我们开始介绍另外一种调度器SchedulerChoreography。
SchedulerClassic调度器
SchedulerChoreography创建Processor,会分2部分创建,一部分是有本地队列的Processor,一部分是协程池的Processor。
voidSchedulerChoreography::CreateProcessor(){for(uint32_ti=0;i<proc_num_;i++){autoproc=std::make_shared<Processor>();// 1. 绑定ChoreographyContext
autoctx=std::make_shared<ChoreographyContext>();proc->BindContext(ctx);SetSchedAffinity(proc->Thread(),choreography_cpuset_,choreography_affinity_,i);SetSchedPolicy(proc->Thread(),choreography_processor_policy_,choreography_processor_prio_,proc->Tid());pctxs_.emplace_back(ctx);processors_.emplace_back(proc);}for(uint32_ti=0;i<task_pool_size_;i++){autoproc=std::make_shared<Processor>();// 2. 绑定ClassicContext
autoctx=std::make_shared<ClassicContext>();proc->BindContext(ctx);SetSchedAffinity(proc->Thread(),pool_cpuset_,pool_affinity_,i);SetSchedPolicy(proc->Thread(),pool_processor_policy_,pool_processor_prio_,proc->Tid());pctxs_.emplace_back(ctx);processors_.emplace_back(proc);}}
再看SchedulerChoreography如何分发任务。
boolSchedulerChoreography::DispatchTask(conststd::shared_ptr<CRoutine>&cr){// 1. 根据协程id,获取协程的锁
...// 2. 设置优先级和协程绑定的Processor Id
if(cr_confs_.find(cr->name())!=cr_confs_.end()){ChoreographyTasktaskconf=cr_confs_[cr->name()];cr->set_priority(taskconf.prio());if(taskconf.has_processor()){cr->set_processor_id(taskconf.processor());}}...uint32_tpid=cr->processor_id();// 3. 如果Processor Id小于proc_num_,默认Processor Id为-1
if(pid<proc_num_){// 4. 协程放入上下文本地队列中
static_cast<ChoreographyContext*>(pctxs_[pid].get())->Enqueue(cr);}else{cr->set_group_name(DEFAULT_GROUP_NAME);// 5. 协程放入ClassicContext协程池队列中
{WriteLockGuard<AtomicRWLock>lk(ClassicContext::rq_locks_[DEFAULT_GROUP_NAME].at(cr->priority()));ClassicContext::cr_group_[DEFAULT_GROUP_NAME].at(cr->priority()).emplace_back(cr);}}returntrue;}
疑问:
- cr->processor_id()的默认值为"-1",而vector访问越界的时候不会报错,本来应该放入全局队列中的???
ChoreographyContext上下文
ChoreographyContext中的调度就非常简单了。
std::shared_ptr<CRoutine>ChoreographyContext::NextRoutine(){// 1. 从本地队列中取出协程
ReadLockGuard<AtomicRWLock>lock(rq_lk_);for(autoit:cr_queue_){autocr=it.second;if(!cr->Acquire()){continue;}if(cr->UpdateState()==RoutineState::READY){returncr;}cr->Release();}returnnullptr;}
ChoreographyContext中"Wait"和"Notify"方法与ClassicContext类似,这里就不展开了。
总结
- SchedulerClassic 采用了协程池的概念,协程没有绑定到具体的Processor,所有的协程放在全局的优先级队列中,每次从最高优先级的任务开始执行。
- SchedulerChoreography 采用了本地队列和全局队列相结合的方式,通过"ChoreographyContext"运行本地队列的线程,通过"ClassicContext"来运行全局队列。
- Processor对协程来说是一个逻辑上的cpu,ProcessorContext实现Processor的运行上下文,通过ProcessorContext来获取协程,休眠或者唤醒,Scheduler调度器实现了协程调度算法。
