

apollo介绍之cyber设计(一)
这是我对Cyber拙劣的模仿
How do you design cyber?
无人驾驶车借鉴了很多机器人领域的技术,我们可以把无人车看做一个轮式机器人。Apollo的计算平台之前一直采用的是ROS,3.5版本用Cyber替换了这一架构,那么如果让我们来重新设计这一个框架,我们需要支持哪些特性呢,我们如何去实现它呢?
- 我们需要一个什么样的系统?
- 如何保证系统的稳定性和灵活性?
- 如何来调试和维护这样复杂的系统?
需求分析
我们先借鉴下ROS的思路:
分布式计算现代机器人系统往往需要多个计算机同时运行多个进程,例如:
- 一些机器人搭载多台计算机,每台计算机用于控制机器人的部分驱动器或传感器;
- 即使只有一台计算机,通常仍将程序划分为独立运行且相互协作的小的模块来完成复杂的控制任务,这也是常见的做法;
- 当多个机器人需要协同完成一个任务时,往往需要互相通信来支撑任务的完成;
单计算机或者多计算机不同进程间的通信问题是上述例子中的主要挑战。ROS为实现上述通信提供两种相对简单、完备的机制。
软件复用随着机器人研究的快速推进,诞生了一批应对导航、路径规划、建图等通用任务的算法。当然,任何一个算法实用的前提是其能够应用于新的领域,且不必重复实现。事实上,如何将现有算法快速移植到不同系统一直是一个挑战,ROS 通过以下两种方法解决这个问题。
- ROS 标准包(Standard Packages)提供稳定、可调式的各类重要机器人算法实现。
- ROS通信接口正在成为机器人软件互操作的事实标准,也就是说绝大部分最新的硬件驱动和最前沿的算法实现都可以在ROS中找到。例如,在ROS的官方网页上有着大量的开源软件库,这些软件使用ROS通用接口,从而避免为了集成它们而重新开发新的接口程序。
综上所述,开发人员将更多的时间用于新思想和新算法的设计与实现,尽量避免重复实现已有的研究结果。
快速测试为机器人开发软件比其他软件开发更具挑战性,主要是因为调试准备时间长,且调试过程复杂。况且,因为硬件维修、经费有限等因素,不一定随时有机器人可供使用。ROS提供两种策略来解决上述问题。
- 精心设计的ROS系统框架将底层硬件控制模块和顶层数据处理与决策模块分离,从而可以使用模拟器替代底层硬件模块,独立测试顶层部分,提高测试效率。
- ROS 另外提供了一种简单的方法可以在调试过程中记录传感器数据及其他类型的消息数据,并在试验后按时间戳回放。通过这种方式,每次运行机器人可以获得更多的测试机会。例如,可以记录传感器的数据,并通过多次回放测试不同的数据处理算法。在 ROS 术语中,这类记录的数据叫作包(bag),一个被称为rosbag的工具可以用于记录和回放包数据。
- 用户通常通过台式机、笔记本或者移动设备发送指令控制机器人,这种人机交互接口可以认为是机器人软件的一部分。
采用上述方案的一个最大优势是实现代码的“无缝连接”,因为实体机器人、仿真器和回放的包可以提供同样(至少是非常类似)的接口,上层软件不需要修改就可以与它们进行交互,实际上甚至不需要知道操作的对象是不是实体机器人。
参考上述实现,我们可以把需求细化为以下几个方面:
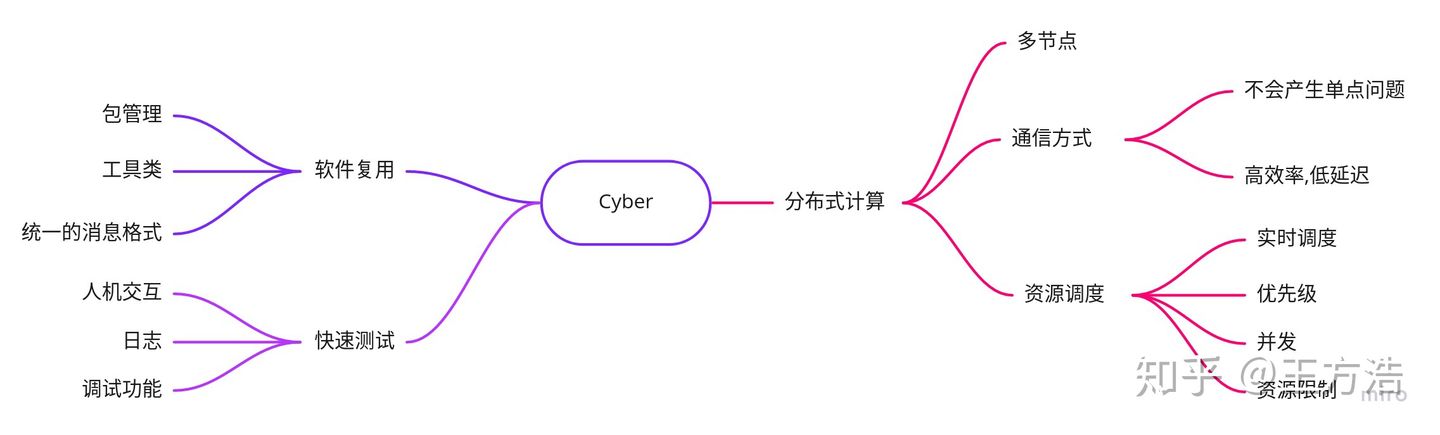
实际上Apollo主要用到了ROS消息通信的功能,同时也用到了录制bag包等一些工具类。所以目前Cyber的首要设计就是替换ROS消息通信的功能。
系统设计
随意的假设
按照上述需求,我们可以随便假想,或者根据自己的理解先画出系统的草图,这里我们要实现一个分布式的系统:
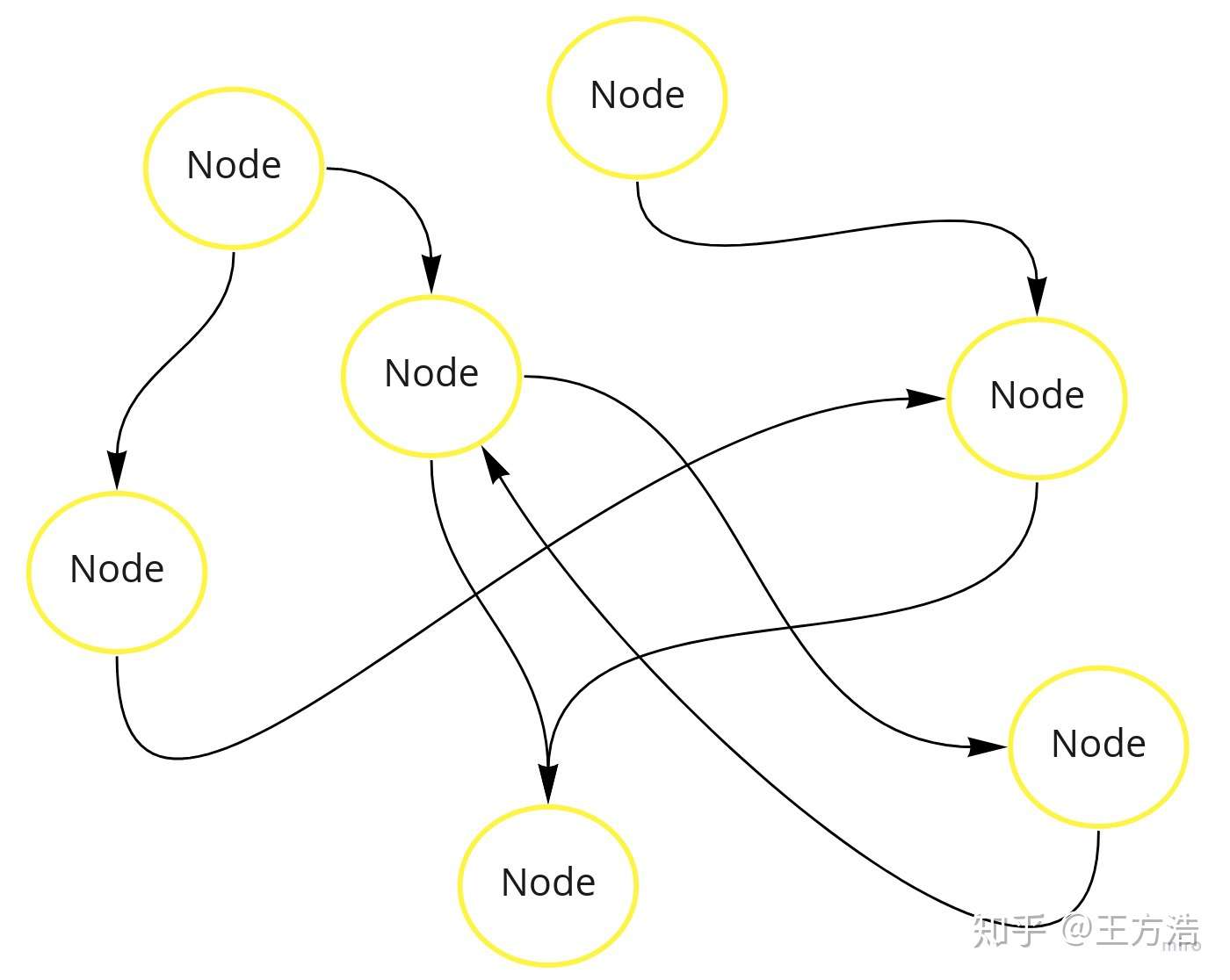
- 上述的系统是一个分布式系统,每个节点作为一个Node。
- 上述系统每个节点之间都可以相互通信,一个节点下线,不会导致到整个系统瘫痪。
- 上述系统可以灵活的增加删除节点。
那么我们再看下其他的设计方式:
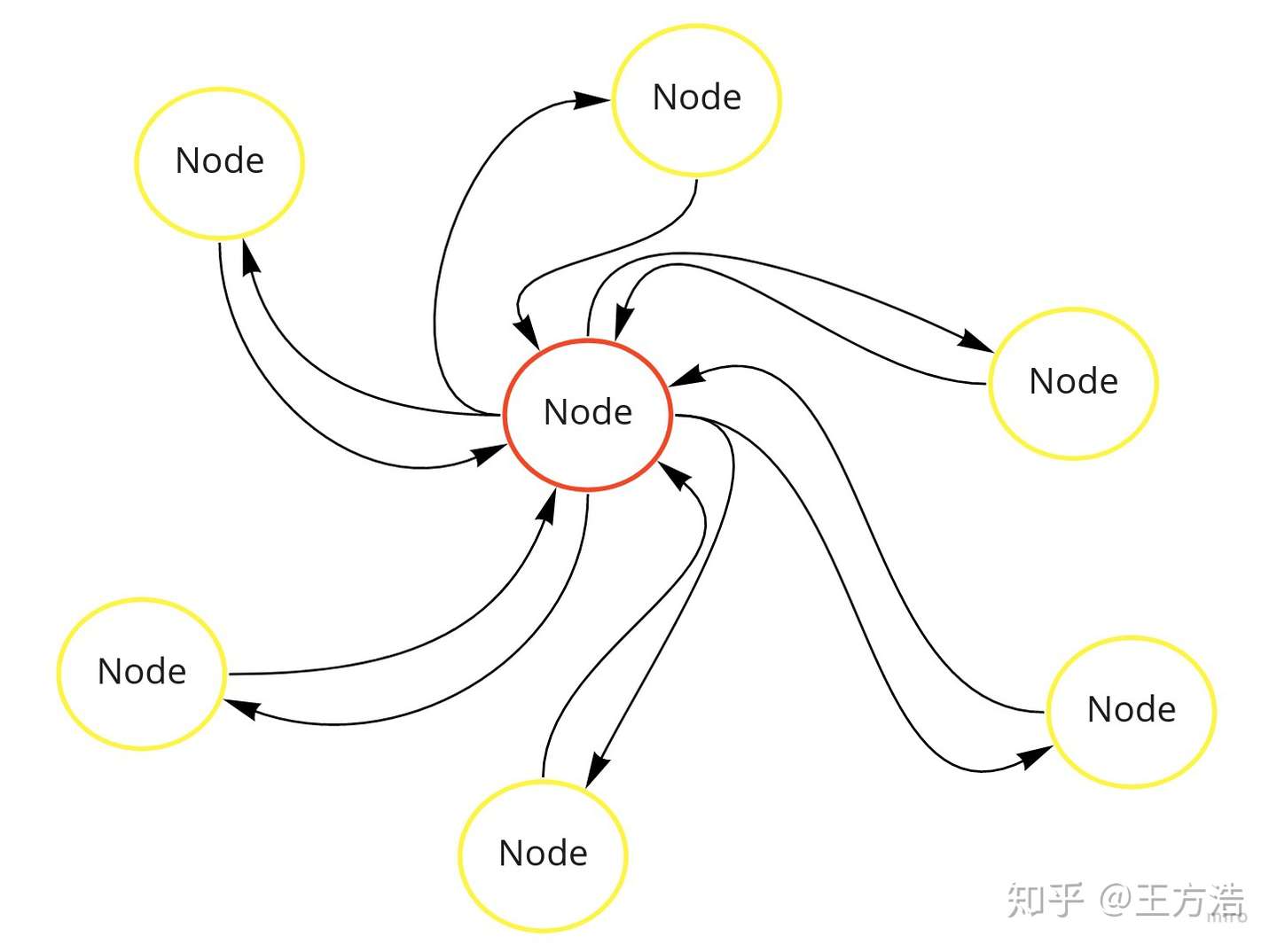
上述系统采用了集中式的消息管理,每个节点之间通讯必须经过主节点来转发对应的消息,如果主节点下线,那么所有的节点都会通信失败,导致系统瘫痪。
- 上述系统是一个分布式系统,每个节点作为一个Node。
- 上述系统每个节点通过主节点通信,主节点下线会导致系统奔溃。
- 上述系统可以灵活的增加删除节点。
对上述系统,一个补救措施就是在增加一个主节点,作为备份,当主节点下线时,启动备份主节点。
这2种方式的主要区别就是通信方式的区别。
当然集中式的消息管理是否有好处呢?集中式的消息处理天然支持管理节点的功能,而点对点的消息处理不支持。例如:
- 当一个节点有10s没有发送消息,那么集中式的消息可以监控并且知道这个节点是否出故障了;
- 集中式的消息可以知道哪些节点在线去找到这些节点,这在多机网络通信的时候很管用,节点只需要注册自己的IP地址,然后由管理节点告诉你去哪里拿到消息。
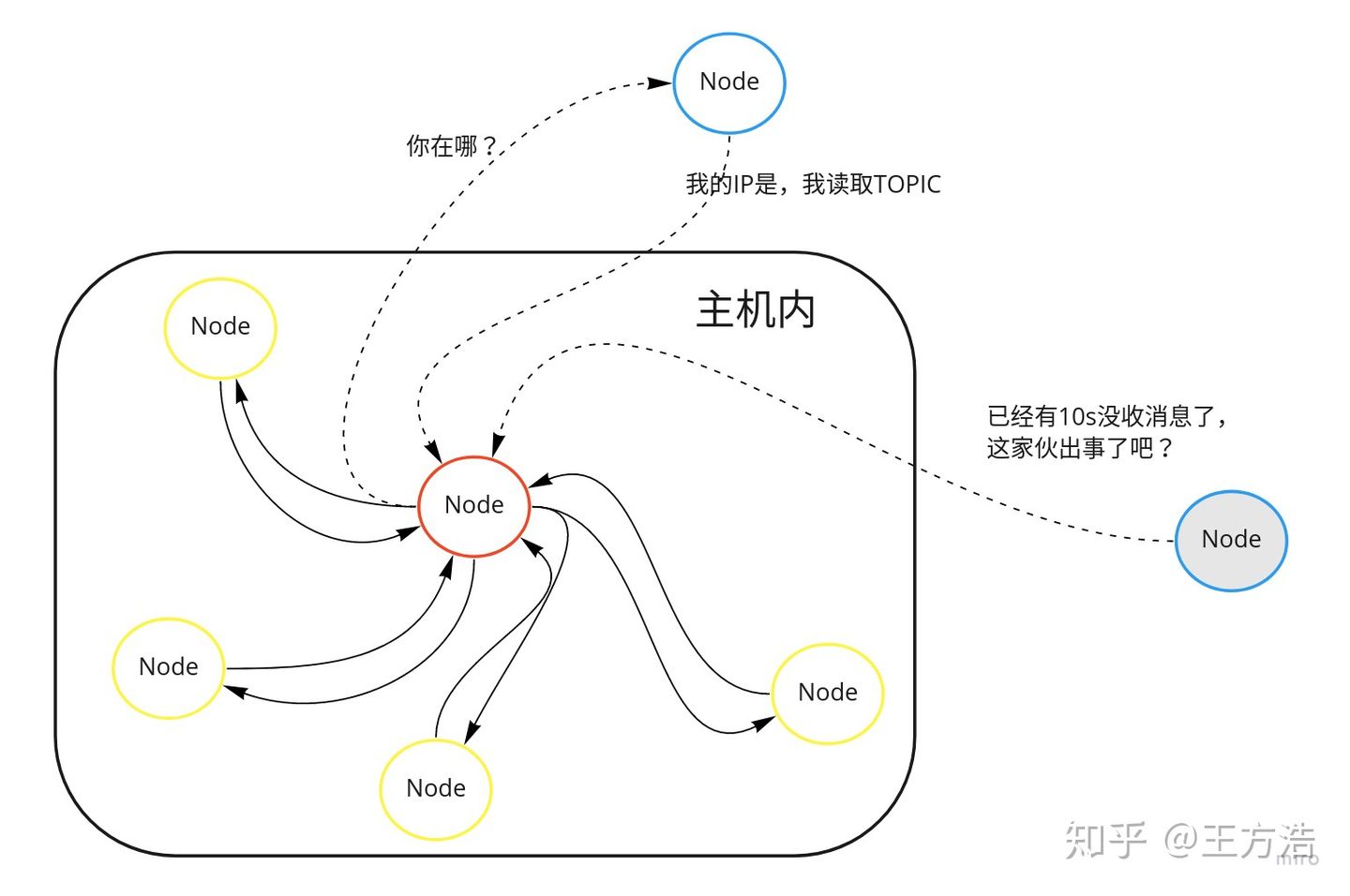
上述只是一个初步的想法,那么基于上面的启发,我们针对上述的每项需求,完成我们的系统设计。
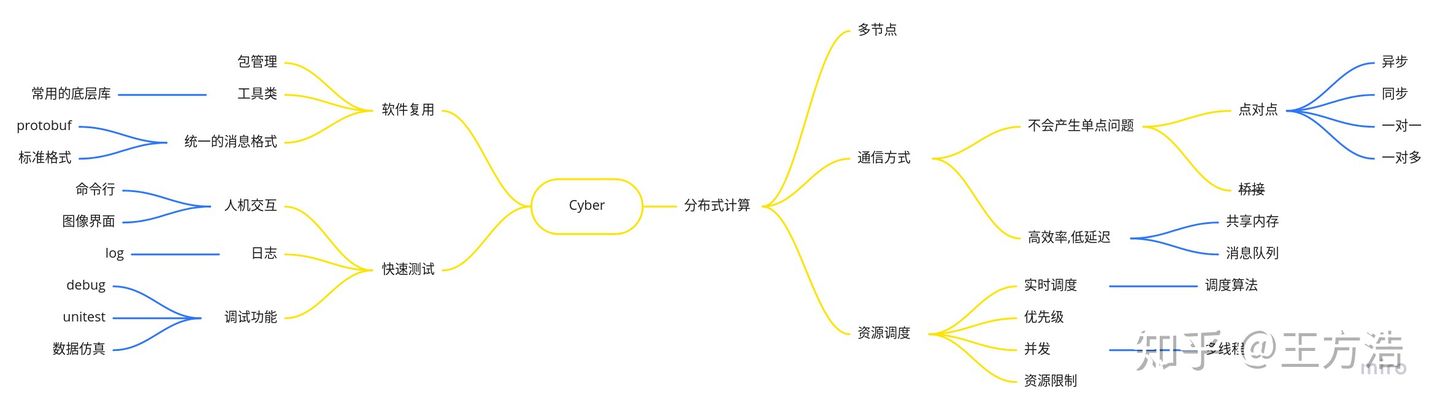
多节点
- 节点管理
- 节点依赖
通信方式
- 点对点
- 采用共享内存的方式可以提高效率,需要注意并发访问时候的问题
资源调度
- 进程调度算法改为实时算法:linux目前的调度是Completely Fair Scheduling(CFS) 算法,需要改为实时的调度算法。
- 进程有优先级
- 支持并发
- 能够限制系统的资源占用
linux进程调度
操作系统最基本的功能就是管理线程,linux的线程调度采用的是CFS(Completely Fair Scheduler)算法,我们先看下没有调度和有调度的情况下的差异。
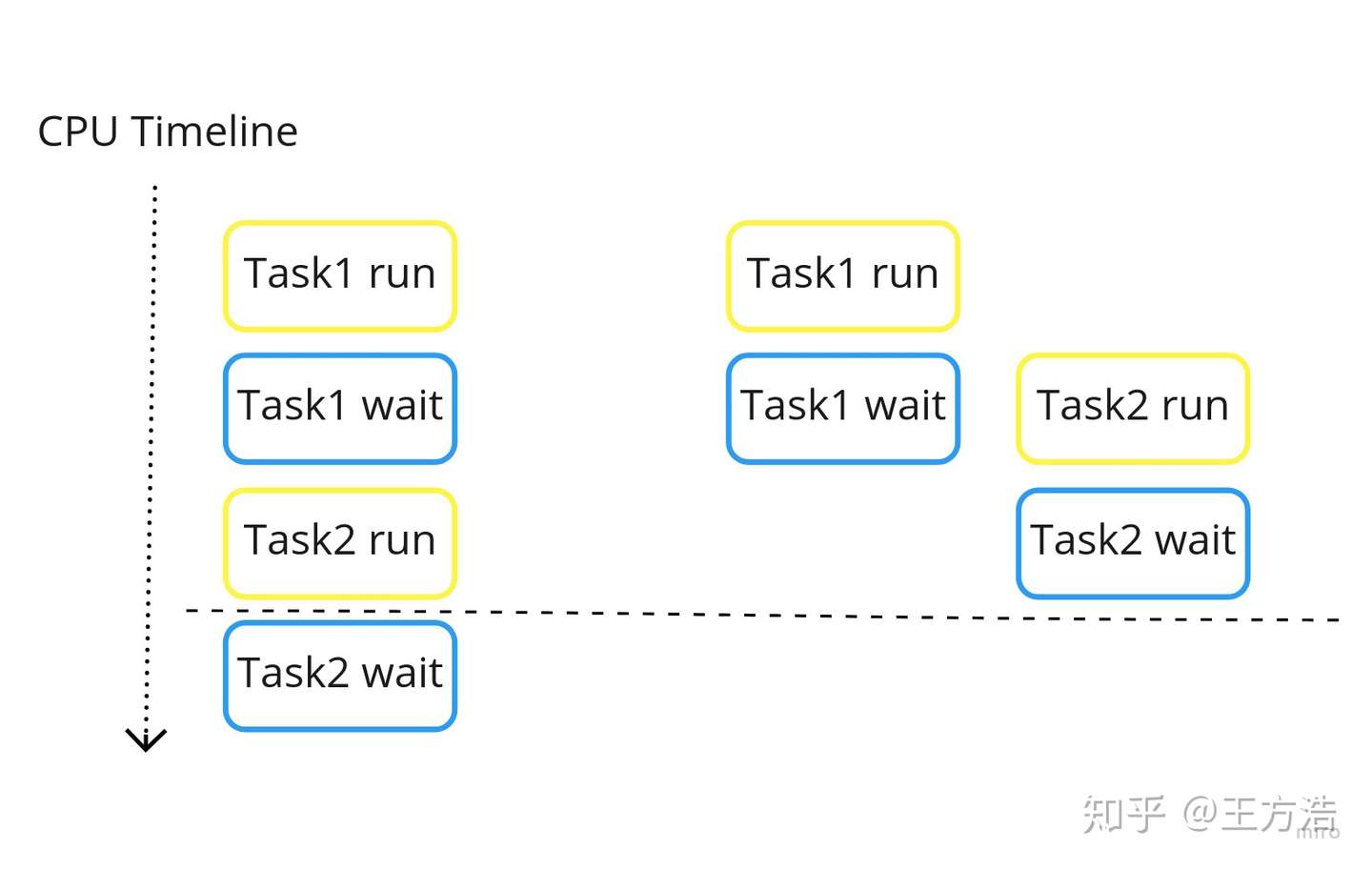
上述是单个CPU核心的情况下,左边是没有CPU调度的情况,任务1在进行完计算之后,会读取内存或者IO的数据,这时候CPU会进入等待状态,CPU在等待的时候没有做任何事情。而右边采用了调度策略,在CPU等待的过程中,任务1主动让出CPU,这样下一个任务就可以在当前任务等待IO的过程中执行,可以看到对任务的调度合理的利用了CPU,使得CPU的利用率更高,从而使任务执行的更快。
linux内核又分为可以抢占的和非抢占的,非抢占的内核禁止抢占,即在一个任务执行完成之前,除非他主动让出CPU或者执行完成,CPU会一直被这个任务占据,不能够被更高优先级的任务抢占。而抢占式的内核则支持在一个任务执行的过程中,如果有更高优先级的任务请求,那么内核会暂停现在运行的任务,转而运行优先级更高的任务,显然抢占式的内核的实时性更好。
CPU把任务根据优先级划分,并且划分不同的时间片,通过时间片轮转,使CPU看起来在同一时间能够执行多个任务,就好像一个人同时交叉的做几件事情,看起来多个事情是一起完成的一样。每个进程会分配一段时间片,在当前进程的时间片用完的时候,如果没有其他任务,那么会继续执行;如果有其他任务,那么当前任务会暂停,切换到其他任务执行。这样带来一个问题就是如何判断进程的优先级。
内核把任务做了区分,分为交互型和脚本型,如果是交互型的进程,对实时性的要求比较高,但是大部分情况下又不会一直运行,典型的情况是,键盘输入的情况,大部分情况下键盘可能没有输入,但是一旦用户输入了,又要求能够立刻响应,否则用户会觉得输入很卡顿。而脚本型因为一直在后台运行,对实时性的要求没那么高,所以不需要立刻响应。linux通过抢占式的方式,对任务的优先级进行排序,交互型进程的优先级要比脚本型进程的优先级要高。从而在交互性进程到来之前能够抢占CPU,优先运行。还有一类是实时进程,这类进程的优先级最高,实时进程必须要保证执行,因此会有限抢占其他进程。
如果单纯的根据优先级,低优先级的任务可能很长一段时间都得不到执行,因此需要更加公平的算法,在一个进程等待时间太长的时候,会动态的提高它的优先级,如果一个进程执行很长的一段时间了,那么会动态降低它的优先级,这样带来的好处是,不会导致低优先级的长期得不到CPU,而高优先级的CPU长期霸占CPU,linux采用的就是CFS(Completely Fair Scheduler)算法,通过该算法可以保证进程能够相对公平的占用CPU。
同时在多CPU和多核场景下,由于每个核心的进程调度队列都是单独的,那么会导致一个问题,如果任务都集中在某一个CPU核心,而其他的CPU核心的队列都是空闲状态,这样也会导致CPU的性能低下,在这种情况下,linux会把任务迁移到其他CPU核心,使得CPU之间的负载均衡,linux引入了Cgroups用来限制,控制与分离一个进程组群的资源(如CPU、内存、磁盘输入输出等)。当然,线程迁移会带来开销,有些时候我们会绑定任务到某一个核心,防止线程迁移。同时如果系统频繁的中断,CPU会频繁停下任务去处理中断,有些场景(网络设备)需要频繁处理网络中断的情况下,通常会绑定中断到某一个CPU核心,这样其他的核心就不会频繁中断,减少了进程切换的开销。
无人驾驶线程调度
参考linux的线程调度,我们也可以思考下无人驾驶线程调度的算法。
我们假设有如下线程:定位,感知,规划,控制,传感器读取,日志,地图(这只是对任务的抽象,当然系统的进程不可能只有这么几个)。假设目前的CPU只有16个核心,那么我们如何规划这些任务的优先级呢?
1. 首先,我们假设定位,感知,规划和控制,传感器读取的优先级比日志和地图更高。这也很容易理解,打不打日志和地图读取的慢点对系统的影响不大,而上述的模块如果读取的很慢,则会导致系统故障。
2. 接下来我们再看优先级高的模块,因为目前我们只有2核心,所以不可能同时执行上述所有模块,只能通过时间片轮转来实现。这里就引入了一个问题,如果分配的时间片太长,会导致响应不及时,如果分配的时间片太短,又会导致线程切换开销,需要折中考虑。如果运行过程中感知和规划正在执行,并且分配的时间片还没有用完,那么控制模块不会抢占CPU,直到运行中的模块时间片用完。
3. 对这些模块的算法复杂度有要求,如果感知模块采用了复杂度较高的算法提高准确率,这样导致的结果是感知会占用更多的CPU时间,其他模块每次需要和感知模块竞争CPU,结果就是导致总体的执行时间会变长。比如,规定感知只需要在200ms的时候处理完任务就可以了,之前感知的算法实现是100ms,而控制模块的时间是100ms,CPU的时间片是50ms,那么感知需要16个时间片,控制需要16个时间片,总的需要时间是200ms,控制模块完成的时间由于时间片轮转,可能是150ms。但是如果感知为了提高效果,增加了算法的复杂度,运行时间改为200ms,感知模块照常能够完成自己的任务,因为只要200ms完成任务,感知模块就完成了任务,总的需要的时间可能是300ms,但是引入的另外的问题是由于竞争控制模块可能完成的时间是200ms,这样就会导致控制模块的时延达不到要求。其实这样的情况总的来说一是需要升级硬件,比如增加CPU的核数;另外的办法就是降低系统算法的复杂度,每个模块的任务要竟可能的高效。
4. 通过上面的要求也可以看到,系统进程的算法复杂度要尽可能的稳定,不能一下子是50ms,一下子是200ms,或者直接找不到最优解,这是最坏的情况,如果各个模块的算法都不太稳定,带来的影响就是当遇到极端情况,每个模块需要的时间都变多时候,系统的负载会一下子变高,导致模块的相应不及时,这对自动驾驶是很致命的问题。
5. 上述是理想情况下,那么我们会遇到哪些情况,系统的进程会奔溃或者一直占用CPU的情况呢?
- 找不到最优解,死循环。大部分情况下程序没有响应是因为找不到最优解,或者死循环,这种状态可以通过代码和算法实现保证。
- 堆栈溢出,内存泄露,空指针。这种情况是由于程序编写错误,也可以通过代码保证。
- 硬件错误。极小概率的情况下,CPU的寄存器会出错,嵌入式(powerpc)的CPU都会有冗余校正,而家用或者服务器(intel)没有这种设计,这种情况下只能重启进程,或者硬件。
我们根据上述的思路,可以得到如下图所示:
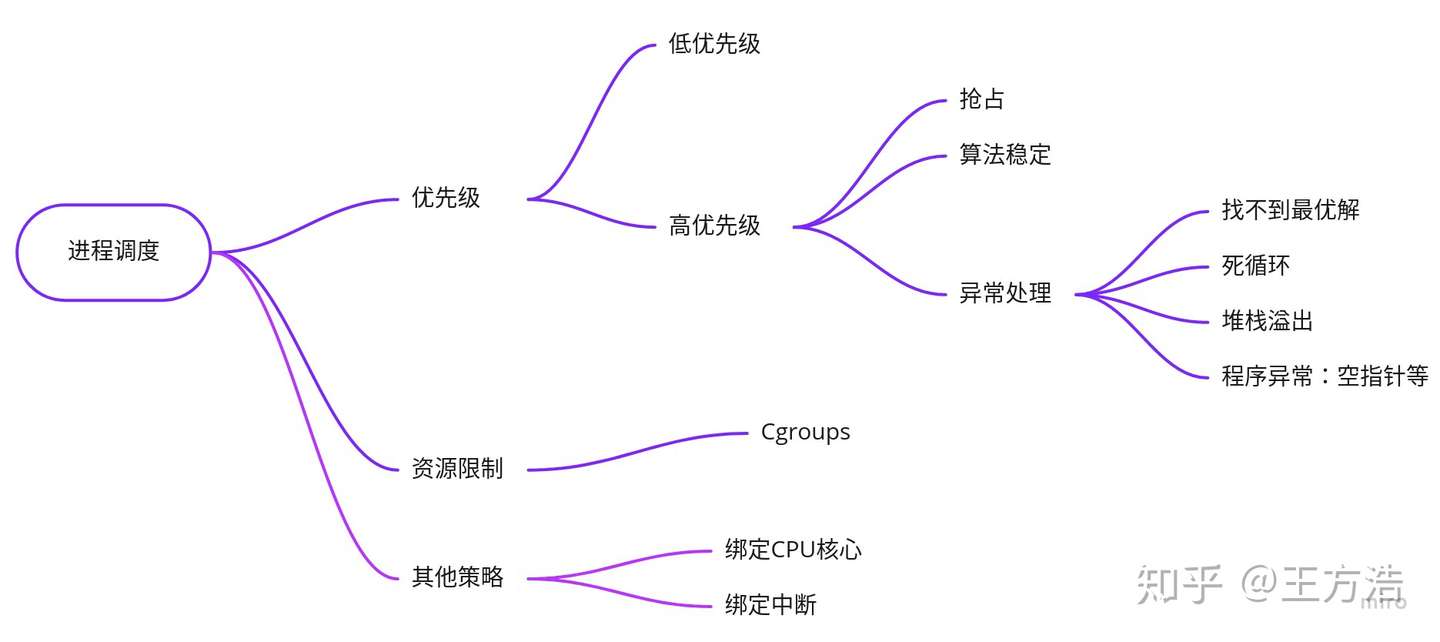
- 把控制的优先级设置到最高,规划其次,感知和定位的优先级设置相对较低,因为控制和规划必须马上处理,感知如果当前帧处理不过来,大不了就丢掉,接着处理下一帧。当然这些线程都需要设置为实时进程。而地图,日志,定位等的优先级设置较低,在其他高优先级的进程到来时候会被抢占。
- Canbus等传感器数据,可以绑定到一个CPU核心上处理,这样中断不会影响到其他核心,导致频繁线程切换。
- 对线程设置cgroups,可以控制资源使用,设置优先级等。
- 测试算法的时间复杂度,是否稳定。
linux性能优化
linux自带了perf可以采样一段时间的系统调用,输出文件再结合火焰图,可以查看当前系统的调用情况,各个线程对cpu的使用情况,然后进行优化。
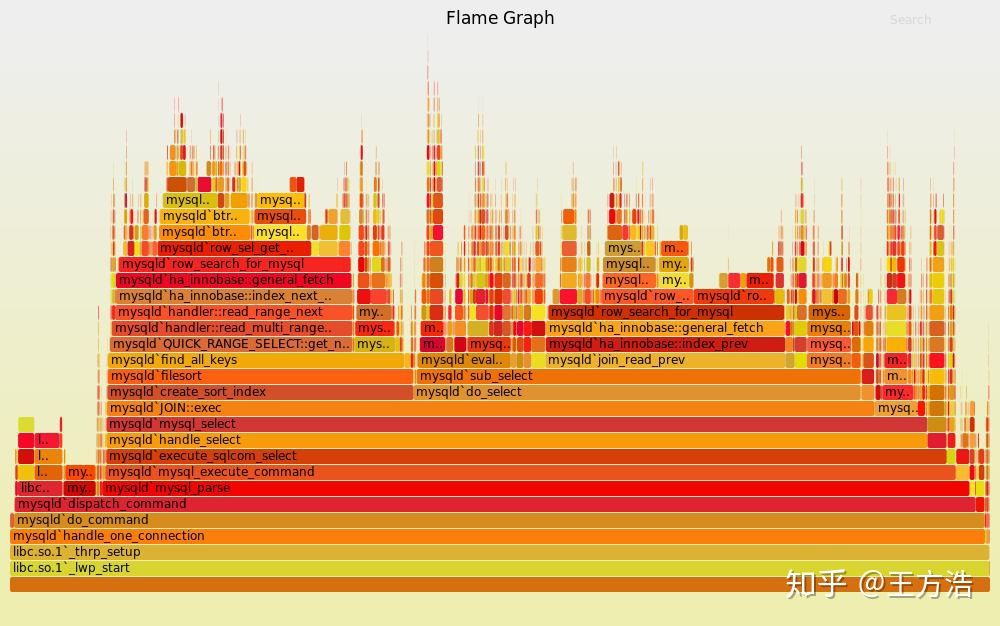
图片引用自阮一峰《如何读懂火焰图?》
最后要了解调度算法,可以参考这篇开山之作。
软件复用
- 包管理
- 工具类
快速测试
- 人机交互
- 日志
- 调试功能
- 通信接口
其他
云平台
如果需要监控线上无人车的状态,那么需要无人车提供连接到云的能力,即发送消息和接收消息的能力。Cyber需要支持能够发送消息给云端,并且接收来自云端消息的能力。
