
The Critical Need for Full AI Model Transparency
Throughout this series, we’ve highlighted the many aspects of open AI, emphasizing the critical role of accessibility and transparency in AI development. A recurring theme is the need for full openness, which is often undermined by the selective disclosure of certain model components.
Some models labeled as “open” lack key components necessary for full understanding and reproduction, limiting further development and innovation. To ensure reliability and safety, users and developers need access to all aspects of an AI model. Without full transparency, the community misses out on opportunities to improve or adapt existing AI technologies for new applications.
The Model Openness Framework (MOF)
The MOF addresses this challenge of incomplete AI model releases by mandating the disclosure of all essential components including datasets, source code, model architectures, and trained parameters.
The MOF mandates the release of complete datasets, fully functional source code, detailed model architectures, and trained parameters, ensuring that every essential element for replicating results is openly available. This comprehensive access allows independent replication, critical for identifying errors, biases, and disparities in models, thus improving scientific rigor. Additionally, the framework promotes the release of all model components under permissive licenses, enabling broader adoption and adaptation. This approach not only allows developers to build on existing models without legal or technical barriers but also highlights your role in fostering an environment of open collaboration, making you an integral part of the AI development process.
The framework guides researchers and developers seeking to enhance model transparency and reproducibility while allowing permissive usage to enhance the AI models’ useability and foster an ecosystem where advancements are built on transparent and openly shared foundations.
The Model Openness Tool (MOT)
To operationalize the MOF, the Model Openness Tool offers a structured methodology for evaluating the completeness and openness of AI models. This tool helps developers self-assess their models against the MOF standards and assists users in identifying models that fully comply with open AI principles. The MOT:
- Assesses Model Components: Evaluates whether all necessary components have been released as per MOF guidelines.
- Classifies Openness: Categorizes models based on their level of openness, offering badges to models that meet high standards of transparency.
- Promotes Standard Adoption: Encourages developers to adopt open AI practices by highlighting the benefits of complete openness in model development.

We Invite You to Shape the future
Get involved with the Model Openness Framework (MOF) today and help shape the future of responsible AI development. By participating, you contribute to a movement that emphasizes transparency and equity in AI technologies.
This series has highlighted the critical need for frameworks and tools like the MOF and the Model Openness Tool (MOT). As we look to the future, achieving truly open AI will require ongoing collaboration, innovation, and a strong commitment to transparency and inclusivity in AI development.” — Ibrahim Haddad, PhD, Executive Director, LF AI & Data
Check out previous posts from this blog series below.
- Addressing Challenges in Open AI with LF AI & Data: Introducing the Model Openness Framework and Tool
- Part II of Addressing the Challenges of Open AI: Navigating Open Source Licenses for Non-Software Assets with LF AI & Data
- Part III of Addressing the Challenges of Open AI: Balancing Innovation with Regulation through the Model Openness Framework
- Part IV of Addressing the Challenges of Open AI: Adding Clarity to AI Model Licenses with MOF
LF AI & Data Resources
- Learn about membership opportunities
- Explore the interactive landscape
- Check out our technical projects
- Join us at upcoming events
- Read the latest announcements on the blog
- Subscribe to the mailing lists
- Follow us on or
Access other resources on LF AI & Data’s or Wiki.
]]>Beyond Metadata: The Rise of Comprehensive Data Governance
The session began with an exploration of how data catalogs have evolved from basic metadata managers, such as the Hive metastore, to robust systems capable of comprehensive data governance. Unity Catalog has expanded its metadata management capabilities to encompass a wide range of data types, including not only traditional tables but also machine learning models, PDFs, and more. This evolution marks a shift towards platforms that facilitate complex transaction management and seamless integration across diverse data assets.
Addressing Technical Challenges with Unity Catalog
Unity Catalog’s development has been a significant advancement in supporting multiple data formats, overcoming challenges to provide unified governance across diverse data assets. Its ability to seamlessly manage structured data, machine learning models, unstructured files, and more is critical for enterprises that require robust governance, compliance, and integration across their entire data landscape. This evolution ensures consistent oversight while addressing the complexity of managing heterogeneous data types.
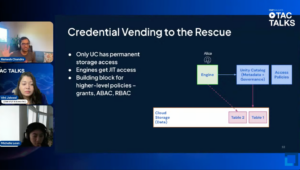
Credential Vending: A Key Security Feature
A highlight of the discussion was the introduction of credential vending, a security feature that enhances governance by granting scoped, time-limited access to data. This mechanism is particularly vital in large-scale environments, where precise management of access is essential to maintain high security and compliance standards.
Open Collaboration and Community Enhancements
The session also highlighted the Unity Catalog’s rich integration capabilities, notably with platforms like Spark and MLflow. The emphasis was on the value of community involvement in expanding and refining Unity Catalog’s capabilities. Active participation in development discussions and community meetups was encouraged, positioning Unity Catalog as a collaborative, open-source project.
Looking Ahead: Future Developments
The discussion concluded with an overview of the roadmap for Unity Catalog, noting upcoming features such as enhanced ML model support and broader data platform integrations. The ongoing development of Unity Catalog is focused on meeting the evolving demands of modern data governance. It invites the community to actively contribute to its growth and enhancement, ensuring the platform continues to adapt to emerging data management challenges and industry requirements.all to the community to contribute to its growth and enhancement.
Get Involved
Unity Catalog thrives on community involvement, and there are multiple ways to contribute and engage:
- GitHub Discussions: Join the on GitHub to propose new features, report issues, or discuss system enhancements.
- Community Meetups: Participate in to learn more about recent developments and network with other users and developers.
- Documentation Contributions: Help improve the documentation by suggesting edits or writing new content to assist new users.
- Code Contributions: For those who want to dive deeper, contributing code to the Unity Catalog can help enhance its functionality and integration capabilities.
Conclusion
The TAC Talks session provided a deep understanding of Unity Catalog’s pivotal role in contemporary data governance. As data ecosystems become more complex, tools like Unity Catalog are crucial for managing governance at scale. For those invested in the future of data management, engaging with the Unity Catalog project offers an opportunity to influence and shape the next generation of data governance tools.
Join us for future TAC Talks, held biweekly on Tuesdays, streamed live via LF AI & Data’s and channels.
LF AI & Data Resources
- Learn about membership opportunities
- Explore the interactive landscape
- Check out our technical projects
- Join us at upcoming events
- Read the latest announcements on the blog
- Subscribe to the mailing lists
- Follow us on or
Access other resources on LF AI & Data’s or Wiki.
]]>

What is RYOMA?
RYOMA is designed to solve complex data problems efficiently and robustly. By leveraging advanced AI techniques, RYOMA streamlines the entire data lifecycle, from data ingestion and preprocessing to analysis and decision-making. It empowers organizations to maximize the value of their data, enabling them to tackle even the most challenging use cases with ease.
Built with scalability and flexibility in mind, RYOMA can be tailored to fit a wide range of industries and applications, making it a versatile tool for businesses aiming to stay ahead in the competitive landscape. Whether you’re working with structured or unstructured data, RYOMA’s agentic capabilities ensure that your data is handled with precision and intelligence.
RYOMA integrates a variety of technologies and frameworks to enhance data analysis, engineering, and visualization including , Reflex, , , Amundsen, , and .
Amplifying RYOMA’s Impact through LF AI & Data Collaboration
Joining the LF AI & Data Foundation as a Sandbox-stage project offers RYOMA the opportunity to tap into the rich resources and collaborative environment that our community provides. By being part of this ecosystem, RYOMA will benefit from:
- Community Collaboration: Access to a global network of developers, data scientists, and industry experts who can contribute to the project’s growth and development.
- Open-Source Governance: A structured and transparent governance model that ensures the project’s direction aligns with community needs and best practices.
- Resource Support: Leverage LF AI & Data’s infrastructure, marketing, and legal resources to accelerate project adoption and impact.
- Exposure and Outreach: Increased visibility within the open-source community and among potential adopters through LF AI & Data’s extensive outreach channels.
“Contributing RYOMA to LF AI & Data marks an important milestone for our project. The LF AI & Data ecosystem offers an unparalleled platform for collaboration and innovation, and we are eager to work with the community to further enhance RYOMA’s capabilities. We are confident that with the support of LF AI & Data, RYOMA will become a vital tool for organizations looking to leverage AI in their data strategies.” – Hao Xu, Lead Software Engineer at JPMorgan & Chase
“We are excited to welcome RYOMA to the LF AI & Data Foundation as a Sandbox project. RYOMA represents a significant advancement in AI-powered frameworks, and we believe that its inclusion in our ecosystem will provide tremendous value to our community and beyond. The open-source collaboration model will be instrumental in driving RYOMA’s evolution and adoption across industries.” – Ibrahim Haddad, Executive Director of LF AI & Data
For more information on how to get involved with RYOMA, integrate it into your projects, or stay updated with its developments, please visit the RYOMA or . Join us in making RYOMA a cornerstone of the AI-driven future.
LF AI & Data Resources
- Learn about membership opportunities
- Explore the interactive landscape
- Check out our technical projects
- Join us at upcoming events
- Read the latest announcements on the blog
- Subscribe to the mailing lists
- Follow us on or
Access other resources on LF AI & Data’s or Wiki
]]>Event Overview
The OPEA Demo-palooza was designed to showcase generative AI workflow solutions tailored for enterprise needs. The event featured an agenda packed with expert-led sessions that illustrated how generative AI can streamline operations, enhance decision-making, and foster innovation in various sectors. Each session provided actionable insights and practical tools that businesses can leverage to harness the power of AI, emphasizing scalability, security, and integration with existing technologies.
Speaker Highlights
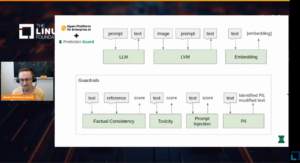
Daniel Whitenack from Prediction Guard discussed the practical challenges businesses faced when adopting AI workflows and the importance of choosing appropriate architectures and components at the enterprise level. He presented Prediction Guard’s platform, which enhanced AI accuracy by integrating data with the latest LLMs and included fact-checking model outputs. His demonstration showcased how Prediction Guard helped enterprises, especially those in sensitive sectors like healthcare and finance, secure their AI implementations. He explained the various components of their AI solutions, such as embeddings for semantic search, LLM integrations, and safeguards against AI malfunctions like prompt injections and toxic outputs.
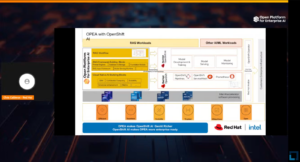
Chris Cauldron from Red Hat detailed the integration of OPEA with Red Hat’s solutions, showcasing how it supported enterprise AI applications through Red Hat’s OpenShift AI platform. He explained how OpenShift AI simplified the deployment, scaling, and management of AI technologies, making enterprise operations more efficient. Chris highlighted Red Hat’s commitment to open source solutions and their practical applications in deploying AI across various industry verticals, ensuring that AI implementations were both scalable and manageable within existing enterprise ecosystems.
Chun Tao and Louie Tsai from Intel introduced an AI avatar built on the OPEA platform, demonstrating the integration of various AI models to enhance human-computer interactions. The demo included capabilities like audio-to-text conversion, understanding language via LLMs, and generating animated video responses, which were crucial for applications in customer service, education, and other public-facing industries.
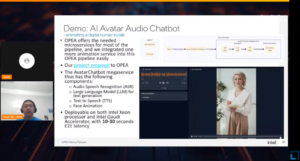
Key Takeaways and Future Outlook
The OPEA Demo-palooza underscored the importance of security, scalability, and seamless integration in deploying AI solutions across enterprise systems. The event highlighted the ongoing efforts of industry leaders to foster a community-driven approach to address complex AI challenges through collaboration and open-source projects. The ongoing development of the OPEA platform promises to bring even more innovations. These initiatives are set to further energize the community and drive forward the integration of AI in enterprise solutions.
Exciting Upcoming Event Series: OPEA Hacktober
This October, OPEA is launching a month-long Hacktober event series, starting with an opening ceremony on September 30th. This fun-filled series is perfect for anyone interested in contributing to GenAI open source, building up the OPEA project, and enhancing their own open source resume. Participants will have the opportunity to deploy applications to major cloud platforms like AWS, Azure, Google Cloud, and Oracle Cloud, and work on packaging these applications for deployment on Kubernetes clusters. The closing ceremonies will be held at OPEA’s GenAI Nightmares event on October 31st. Your contributions will help shape the future of enterprise AI!
Conclusion
OPEA’s Demo-palooza was not only a display of technological innovation but also a testament to the collaborative spirit inherent in the open-source community. As these technologies continue to evolve, they pave the way for more sophisticated and accessible AI applications in business environments, promising significant impacts on efficiency and operational capabilities.
To learn more about OPEA and to get involved, visit the OPEA website and .
LF AI & Data Resources
- Learn about membership opportunities
- Explore the interactive landscape
- Check out our technical projects
- Join us at upcoming events
- Read the latest announcements on the blog
- Subscribe to the mailing lists
- Follow us on or
Access other resources on LF AI & Data’s or Wiki.
]]>
The , a Linux Foundation AI & Data project, has recently made significant strides in developing an innovative AI framework to support individuals with mental health issues. This framework, designed in collaboration with Diego Gosmar, Oita Coleman of the Open Voice Trustmark, and Elena Peretto from Fundació Ajuda i Esperança, provides essential tools for psychologists.
“Insight AI Risk Detection Model, Vulnerable People Emotional Situation Support,” authored by Gosmar, Oita Coleman, and Elena Peretto. This research was presented at the 28th International Conference on Evaluation and Assessment in Software Engineering (EASE 2024) held in Salerno, Italy, and published by ACM in New York, NY, USA.
The paper introduces an AI-based risk detection model designed to provide real-time emotional support and risk assessment, particularly targeting the rise in mental health issues among youth. The model uses Insight AI for Sentiment and Emotional Analysis to evaluate synthetic interactions, drawing on insights from Fundació Ajuda I Esperança’s customer service for vulnerable youth aged 14 to 25. With over 7,000 chat interactions addressing issues like depression, anxiety, and relationship problems, the model underscores the importance of ethical AI use in mental health services and advocates for responsible deployment by non-profit organizations like Fundació Ajuda I Esperança.
The study underscores the growing prevalence of mental health issues worldwide, with approximately 20% of youth affected. The critical shortage of mental health professionals—sometimes as few as one per 10,000 individuals—highlights the urgent need for scalable, immediate emotional support. This gap makes Digital Mental Health Interventions (DMHIs), which provide diagnostics, symptom management, and content delivery, increasingly essential.
The Insight AI Risk Detection Model is a key innovation in this field, developed in collaboration with Fundació Ajuda I Esperança. The model is specifically designed to address the mental health needs of 14- —to 25-year-olds, a group that has seen a 25% rise in reported mental health issues over the past decade. The model uses AI to analyze conversation patterns and offer timely support while also navigating important ethical and legal considerations, such as informed consent and privacy protection.
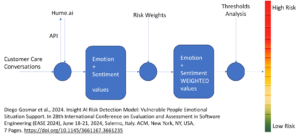
The framework is designed for future enhancement and broader application through AI fine-tuning. It involves improving synthetic conversation generation, customizing via AI Model APIs, and optimizing for specific populations using Sequential Quadratic Programming (SQP) techniques. The AI model’s integration of sentiment and emotion analysis has produced strong results in sentiment analysis, though we still need to refine the emotional analysis.
Deploying such technology, particularly in sensitive areas like mental health support, requires a careful and ethically responsible approach. The model’s development is guided by a strong commitment to ethical principles, including model privacy, data security, and informed consent, which are crucial for its acceptance and scalability.
Two major challenges are addressed:
- The highly sensitive nature of these conversations, which raises privacy concerns,
- Cryptic communication styles are often found in interactions between young people and mental health professionals.
As the model evolves, its real-world application will require ongoing improvement based on feedback from service interactions and continuous collaboration with mental health experts. While the initial results are promising, they represent just the beginning of a broader dialogue and further research into the responsible use of AI in emotional and mental health support.
For those interested in exploring the details, the full paper can be accessed via this .
Diego Gosmar, Elena Peretto, and Oita Coleman. 2024. Insight AI Risk Detection Model: Vulnerable People Emotional Situation Support. In 28th International Conference on Evaluation and Assessment in Software Engineering (EASE 2024), June 18–21, 2024, Salerno, Italy. ACM, New York, NY, USA.
]]>Common Misunderstandings About AI Model Licenses
- One Size Fits All: A prevalent misconception is that a single license can cover all aspects of an AI model — from the data and algorithms to the software and derived models. In reality, different components of an AI model may require different types of licenses, each with its own set of permissions and restrictions.
- Freedom to Operate: Many believe that open-source licenses grant the freedom to use, modify, and distribute AI models without constraints. However, most open-source licenses have conditions and obligations that must be met, such as attribution requirements or restrictions on commercial use.
- Derivative Works: There is often confusion about what constitutes a derivative work in the context of AI models. Modifying an AI model’s code or training an AI model with new data can create derivative works, which may be subject to the original license’s terms.
The Role of the Model Openness Framework (MOF)
The Model Openness Framework (MOF) offers a detailed and structured approach to evaluating AI models, considering not just ethical and regulatory compliance but also licensing transparency. This clarity is essential for users and developers to understand the legal implications of using, sharing, or modifying an AI model.
The MOF Acceptable Licenses table below specifies standard open licenses recommended for releasing components in each category, while allowing some flexibility for equivalent licenses.
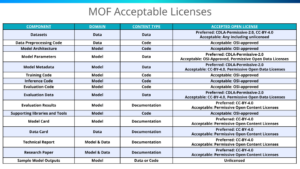
By providing a comprehensive scope, the MOF encourages opening the entire pipeline that produces, evaluates, and applies a model. This approach offers multiple perspectives into the model’s inner workings, promoting transparency and reproducibility in open model development.
The Role of the Model Openness Tool (MOT)
Building on the principles of the MOF, the Model Openness Tool (MOT) provides a practical solution for applying the framework. offers a practical way to apply the framework. MOT enables users and developers to assess the openness and licensing status of AI models by generating a detailed score. This score reflects how well a model meets the MOF criteria, including transparency, fairness, and legal compliance.
Get Involved
The complexities of AI licensing are a significant barrier to the widespread adoption and ethical use of artificial intelligence. By addressing the common misunderstandings surrounding these issues, the Model Openness Framework and the Model Openness Tool help pave the way for more responsible, innovative, and collaborative AI development.
Get involved with MOF today and help shape the future of responsible AI development. By participating, you contribute to a movement that emphasizes transparency and equity in AI technologies.
- Explore the Model Openness Tool here
- Explore the full Model Openness Framework
- Join the Generative AI Commons community and mailing list
- Advocate for the use of MOF in your organization and network
The next blog will discuss the common misunderstandings regarding license implications for AI models.
LF AI & Data Resources
- Learn about membership opportunities
- Explore the interactive landscape
- Check out our technical projects
- Join us at upcoming events
- Read the latest announcements on the blog
- Subscribe to the mailing lists
- Follow us on or
Access other resources on LF AI & Data’s or Wiki.
]]>Introduction
In today’s software development landscape, efficiently searching through codebases is crucial for productivity. Whether you’re looking for a specific function, debugging an issue, or understanding a new codebase, having a robust code search tool can significantly enhance your workflow. This tutorial will guide you through building a code search engine using purely open-source tools. By leveraging open-source Large Language Models (LLMs), vector search libraries, and sentence embedding models, you can create a powerful and customizable solution.
Building Gen AI Applications with Open Source Tools
While closed-source solutions like OpenAI’s GPT models provide powerful capabilities, it’s possible to achieve similar functionality using open-source alternatives. In this tutorial, we’ll focus on the following open-source tools:
– Ollama (Codestral): An open-source LLM that can generate and understand code.
– Annoy: A library for efficient vector similarity search.
– Sentence BERT: A model for generating sentence embeddings.
Closed Source Equivalents
To understand the significance of these tools, let’s compare them with their closed-source counterparts:
- GPT vs. Codestral: While GPT models from OpenAI are highly advanced, Codestral offers a competitive open-source alternative for code generation and understanding.
- Closed Source Vector Stores vs. Annoy: Closed-source vector stores offer managed services and additional features, but Annoy provides an efficient and scalable open-source solution.
- Embeddings (Ada from OpenAI) vs. Sentence BERT: Ada embeddings from OpenAI are powerful, but Sentence BERT offers a robust and accessible open-source alternative.
Importance of Open Source
Developing with open source tools offers several significant advantages in the field of software engineering and AI application development. Firstly, open source alternatives provide competitive functionality to powerful closed-source solutions, enabling developers to build advanced applications while maintaining independence from proprietary platforms. This democratizes access to cutting-edge technologies and allows for more diverse and innovative solutions. Secondly, open source tools typically offer greater flexibility and customization options, empowering developers to tailor solutions precisely to their needs or to the specific requirements of their projects. This adaptability can lead to more efficient workflows and improved productivity. Lastly, engaging with open source technologies fosters a culture of learning and collaboration within the developer community. By working with transparent, modifiable systems, developers can gain deeper insights into underlying technologies, contribute improvements, and participate in a global ecosystem of shared knowledge and resources. These factors combine to make open source development an attractive and powerful approach for building modern software solutions.
Tutorial: Building Embeddings
To build our code search engine, we first need to generate embeddings for our code snippets. Embeddings are numerical representations of text that capture semantic meaning, making it possible to perform similarity searches. The below example is based on the python but steps 2 through 4 are language agnostic.
Step 1: Install Dependencies
Ensure you have the following dependencies installed:
“`bash
pip install ollama sentence-transformers annoy
“`
Step 2: Generate Embeddings with Sentence BERT
We’ll use Sentence BERT to generate embeddings for our code snippets. Here’s a sample script to achieve this:
“`python
from sentence_transformers import SentenceTransformer
import numpy as np
# Initialize Sentence BERT model
model = SentenceTransformer(‘sentence-transformers/all-MiniLM-L6-v2’)
# Sample code snippets
code_snippets = [
“def add(a, b): return a + b”,
“def multiply(a, b): return a * b”,
“def subtract(a, b): return a – b”
]
# Generate embeddings
embeddings = model.encode(code_snippets)
# Save embeddings
np.save(‘code_embeddings.npy’, embeddings)
“`
This script initializes a Sentence BERT model, generates embeddings for a list of code snippets, and saves them to a file.
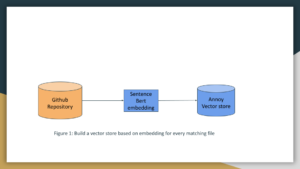
Integrating Annoy for Efficient Search
Annoy (Approximate Nearest Neighbors Oh Yeah) is a library that enables efficient vector similarity searches. We’ll use it to search for code snippets based on their embeddings.
Step 3: Build an Annoy Index
Next, we’ll build an Annoy index using the embeddings generated earlier:
“`python
from annoy import AnnoyIndex
import numpy as np
# Load embeddings
embeddings = np.load(‘code_embeddings.npy’)
# Initialize Annoy index
dimension = embeddings.shape[1]
annoy_index = AnnoyIndex(dimension, ‘angular’)
# Add embeddings to index
for i, embedding in enumerate(embeddings):
annoy_index.add_item(i, embedding)
# Build the index
annoy_index.build(10)
annoy_index.save(‘code_search.ann’)
“`
This script initializes an Annoy index, adds the embeddings, and builds the index for efficient search.
Using Ollama for Code Understanding and Generation
Ollama (Codestral) is an open-source LLM that can understand and generate code. We’ll use it to enhance our code search engine by providing code explanations and generation capabilities. Let’s write the python script that performs search and uses Codestral to generate explanations. This script integrates the components we’ve discussed to perform code searches and generate explanations using Ollama.
“`python
import json
from annoy import AnnoyIndex
from sentence_transformers import SentenceTransformer
import ollama
# Initialize Sentence BERT model
model = SentenceTransformer(‘sentence-transformers/all-MiniLM-L6-v2’)
# Load Annoy index
annoy_index = AnnoyIndex(384, ‘angular’)
annoy_index.load(‘code_search.ann’)
# Load code snippets
with open(‘code_snippets.json’, ‘r’) as f:
code_snippets = json.load(f)
def search_code(query, top_n=5):
# Generate query embedding
query_embedding = model.encode([query])[0]
# Perform search
indices = annoy_index.get_nns_by_vector(query_embedding, top_n)
# Retrieve code snippets
results = [code_snippets[i] for i in indices]
return results
def explain_code(code):
# Use Ollama to generate code explanation
explanation = ollama.generate(code, model=’codestral’)
return explanation
if __name__ == “__main__”:
# Sample query
query = “function to add two numbers”
# Search for code
search_results = search_code(query)
print(“Search Results:”)
for result in search_results:
print(result)
# Generate explanation for the first result
explanation = explain_code(search_results[0])
print(“Code Explanation:”)
print(explanation)
“`
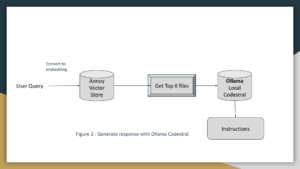
Implementation of this app is based on the work here and here
Conclusion
One limitation of deploying Ollama locally is that we are restricted by the hardware capabilities of the laptop or desktop. By following this tutorial, you’ve learned how to build a code search engine using open-source tools. With Ollama, Annoy, and Sentence BERT, you can create a powerful and efficient search solution tailored to your needs. This approach demonstrates the potential of open-source tools in developing advanced AI applications, offering a viable alternative to closed-source solutions.
References
[1]
[2] https://mistral.ai/news/codestral/
[3]
[4]
[5] https://lablab.ai/event/codestral-ai-hackathon/codebasebuddy/codebasebuddy
[6] https://lablab.ai/event/open-interpreter-hackathon/githubbuddy/codebasebuddy
Author Bio:
Raghavan Muthuregunathan is a member of genaicommons.org, leading the Education & Outreach workstream, also the Applications workstream. Apart from his open source contributions, he leads the Search AI organization at Linkedin. He has authored several articles on entrepreneur.com and is an active reviewer for several journals such as IEEE TNNLS, PLOS ONE, ACM TIST. He is also an active hackathon participant on lablab.ai.
Acknowledgement:
We would like to thank Ofer Hermoni, Santhosh Sachindran and the rest of the Gen AI Commons for thoughtful review comments.
]]>Introducing Monocle: An Eye on GenAI
Monocle is an open source tracing framework to reduce work for developers and bring consistency in monitoring GenAI applications built using distributed components, languages, frameworks and tools. It includes a suite of Python libraries that automatically instrument GenAI application code, with upcoming support for TypeScript. This automation capturestraces without the need for extensive manual coding to reduce work for developers
Not only this, Monocle introduces an observability focused metamodel—a sophisticated way to articulate GenAI application attributes and the interdependencies among various components, such as workflows, models, and cloud infrastructure. This feature ensures a unified view across different technologies and vendors, bringing consistency and significantly simplifying monitoring distributed GenAI applications.
Seamless Integration and Support
Monocle offers out-of-the-box support for multiple GenAI application frameworks and model hosting services, enabling no-code or low-code implementation of tracing functionalities. This comprehensive support framework ensures that developers can easily integrate Monocle into their existing projects, facilitating a smoother transition to production-ready applications. This seamless integration allows developers to focus more on innovation and less on the operational intricacies of their applications.
Comprehensive Tracing and Storage Solutions
Monocle’s tracing capabilities are designed to capture every facet of GenAI application operation, from individual model inferences to complex interactions across multiple components and services. This comprehensive capture ensures that developers have a full spectrum view of their applications’ performance and dependencies.
“Being part of LF AI & Data means Monocle is developed in a transparent, community-driven environment. Everyone building GenAI applications needs monitoring. This open-source model is essential for a foundational industry-wide utility to be shaped by those who use it most – researchers, developers, SREs and organizations involved in making GenAI safe, reliable and impactful.” – Prasad Mujumdar, Co-founder & CTO of Okahu
Community-Driven Development
As a project under the LF AI & Data Foundation, Monocle benefits from the collaborative, open-source model of development. This means it not only evolves based on real-world use cases but also incorporates diverse perspectives and expertise from across the global technology community. Such collaboration is essential for creating robust, versatile tools that can keep pace with the rapid advancements in AI technology.
“Our mission at LF AI & Data is to cultivate an ecosystem where advancements in artificial intelligence and data sciences thrive, supported by impartial technical governance and a neutral hosting organization that manages project assets, offering crucial resources and infrastructure. With the introduction of Monocle, we are thrilled to provide a tool that not only boosts developer productivity but also advances the entire Generative AI field. This project will thrive under open-source neutral governance, ensuring a transparent and collaborative space that fosters rapid innovation while maintaining robust stability and security.” – Ibrahim Haddad, Executive Director of LF AI & Data
Get Involved
We encourage developers and contributors in the AI community to explore Monocle and contribute to its evolution. To learn more about the Monocle project and how you can contribute, please visit the Monocle or .
LF AI & Data Resources
- Learn about membership opportunities
- Explore the interactive landscape
- Check out our technical projects
- Join us at upcoming events
- Read the latest announcements on the blog
- Subscribe to the mailing lists
- Follow us on or
Access other resources on LF AI & Data’s or Wiki
]]>The Challenge: Barriers to GenAI Adoption
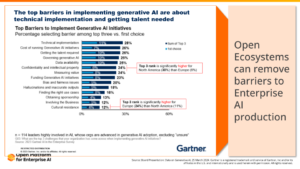
While Generative AI is transforming industries and creating new opportunities, enterprises often need help with several barriers to its adoption. According to Gartner, these obstacles include:
- Technical Implementation: The complexity of implementing GenAI solutions requires specialized knowledge and skills.
- Cost and Talent Requirements: The high cost of computing time and the need for skilled talent pose significant hurdles.
- Security, Privacy, and Transparency: Ensuring robust security, maintaining privacy, and achieving transparency are crucial concerns.
- Ecosystem Fragmentation: The rapid evolution of GenAI technology can lead to fragmentation and interoperability issues.
OPEA addresses these barriers by creating an open ecosystem that fosters collaboration, innovation, and seamless integration.
OPEA’s Vision: Open Ecosystems for Enterprise AI
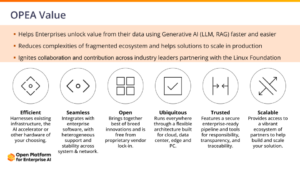
OPEA is built on the belief that open ecosystems are more beneficial than closed ones. By promoting interoperability and collaboration, OPEA seeks to empower enterprises to harness the full potential of GenAI. Here’s how OPEA achieves this:
- Simplifying GenAI Development and Deployment- OPEA combines various modules to streamline GenAI development, focusing on ease of use, return on investment (ROI), security, and end-to-end use case support. The platform simplifies the process, from preparing data and building large language models (LLMs) to deploying and productizing solutions.
- Unlocking Enterprise Value- OPEA enables enterprises to unlock GenAI’s true value by reducing complexities, enhancing collaboration, and driving innovation. By breaking down barriers and providing a comprehensive platform, OPEA helps businesses realize tangible benefits from their AI initiatives.
- Igniting Collaboration and Innovation- OPEA fosters a collaborative ecosystem through its open platform, where partners, tools, and technologies come together to drive interoperability and innovation. The project emphasizes the importance of sharing stories, experiences, and best practices to inspire new ways of implementing GenAI solutions.
The OPEA Platform: A Hub for Innovation
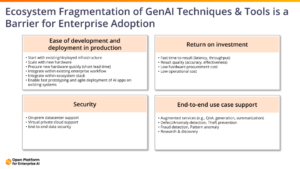
The OPEA platform offers many features and capabilities to support enterprises in their GenAI journey. It includes:
- Ease of Development: Simplified tools and resources to accelerate GenAI development.
- ROI Maximization: Strategies to maximize the return on investment from AI initiatives.
- Security and Privacy: Robust security measures to ensure data protection and privacy.
- End-to-End Use Case Support: Comprehensive support for various use cases and applications.
Join the OPEA Community
Join the OPEA community and become part of this exciting initiative. By collaborating with a diverse group of partners and contributors, you can help shape the future of enterprise AI and drive meaningful impact.
Get Involved
- GitHub Repository: Explore our for code, resources, and collaboration opportunities.
- GenAI Examples: Discover examples and best practices for implementing GenAI solutions.
- GenAI AlInfra: Learn about the infrastructure and technologies powering GenAI.
- GenAI Eval: Participate in evaluations and assessments to enhance GenAI adoption.
Join the Steering Committee and Working Groups
We invite you to join our steering committee and working groups to ensure a broad and diverse perspective. By participating in end-user evaluation, research, security, and community activities, you can contribute to OPEA’s growth and success.
OPEA’s commitment to fostering an open, collaborative ecosystem stands as a beacon for how we can tackle the complexities of AI implementation and unlock its full potential. By simplifying development, enhancing security, and promoting innovation, OPEA is not just providing solutions but also paving the way for enterprises to thrive in the AI-driven future.
Stay tuned for more insights and updates from LF AI & Data’s TAC Talks series, occurring biweekly on Tuesdays at 9AM PDT.
LF AI & Data Resources
- Learn about membership opportunities
- Explore the interactive landscape
- Check out our technical projects
- Join us at upcoming events
- Read the latest announcements on the blog
- Subscribe to the mailing lists
- Follow us on or
Access other resources on LF AI & Data’s or Wiki.
]]>We’re excited to announce the launch of TAC Talks, a new live series designed to spotlight the innovative work happening within the LF AI & Data Foundation. With a focus on promoting the vast array of open-source projects under our umbrella, this initiative is designed to foster deeper understanding and collaboration within the artificial intelligence and data communities.

The LF AI & Data Ecosystem
The LF AI & Data Foundation plays a pivotal role in nurturing and supporting open-source projects in the realms of AI and data. As of August 2024, our community includes 68 projects and 65 member organizations, ranging from startups to global enterprises. These projects cover diverse areas such as machine learning, deep learning, and data management. To get a better grasp of our expansive project portfolio, you can view the full list of projects and explore the project landscape.
Why TAC Talks?
The introduction of TAC Talks is driven by our commitment to:
- Showcase the power of LF AI & Data projects: By highlighting the groundbreaking initiatives and the brilliant minds behind them, we aim to showcase the transformative impact these projects have on technology and industry.
- Democratize access to expertise: We believe in breaking down barriers to information. TAC Talks will provide a platform for project teams to share their knowledge and for the community to engage directly with the forefront leaders in technology.
What to Expect
Hosted by the Chair of the Technical Advisory Council of Linux Foundation’s AI and Data Foundation, Vini Jaiswal, these sessions will feature engaging conversations with project maintainers, leaders and experts, offering valuable insights into the world of open-source AI and data including Generative AI and data engineering.Each TAC Talk will feature a unique format, such as fireside chats, 1:1 conversations, or panel discussions.
The series will run biweekly on Tuesdays at 9 AM PST / 12 PM EST, streamed live on our LinkedIn and YouTube channels. This schedule ensures that our global audience can join and participate actively in these discussions.
Join the Conversation
We invite you to participate in TAC Talks!
- Follow us on our official and for live streams and participate in discussions and Q&A.
- Share your thoughts and feedback on social media using the hashtag #TACTalks #LFAIData.
Let’s Build a Stronger Community Together
Your involvement is key to the success of TAC Talks. We look forward to welcoming you to these sessions, where we can learn, share, and grow together. Together, let’s push the boundaries of what open source and collaborative development can achieve in the AI and data spaces. Join us for TAC Talks and be a part of this transformative journey!
LF AI & Data Resources
- Learn about membership opportunities
- Explore the interactive landscape
- Check out our technical projects
- Join us at upcoming events
- Read the latest announcements on the blog
- Subscribe to the mailing lists
- Follow us on or
]]>